Habilitar o Federador Prometheus
Requisitos
Por padrão, o Federador Prometheus é configurado e destinado a ser implantado junto com monitoramento-rancher, que implanta o Operador Prometheus junto com um Prometheus de Cluster que cada Pilha de Monitoramento de Projeto é configurada para federar métricas com escopo de namespace por padrão.
Para instruções sobre como instalar o monitoramento-rancher, consulte esta página.
A configuração padrão já deve ser compatível com sua pilha de monitoramento-rancher. No entanto, para otimizar a segurança e a usabilidade do Federador Prometheus em seu cluster, recomendamos fazer essas configurações adicionais no monitoramento-rancher:
Assegure-se de que o namespace cattle-monitoring-system esteja colocado no Projeto do Sistema (ou em um Projeto com restrições semelhantes que tenha acesso a outros Projetos no cluster)
O modelo de segurança do Operador Prometheus espera que o namespace em que ele é implantado (por exemplo, cattle-monitoring-system) tenha acesso limitado para qualquer pessoa, exceto Administradores de Cluster, para evitar escalonamento de privilégios por meio da execução em Pods (como os Jobs que executam operações Helm). Além disso, implantar o Federador Prometheus e todas as pilhas Prometheus de Projeto no Projeto do Sistema garante que cada Prometheus de Projeto consiga acessar e coletar cargas de trabalho em todos os Projetos, mesmo que Políticas de Rede sejam definidas por meio da Isolação de Rede do Projeto. Isso também fornece acesso limitado para Proprietários de Projetos, Membros de Projetos e outros usuários, de modo que eles não consigam acessar dados aos quais não deveriam ter acesso (ou seja, ser autorizados a executar em pods, configurar a capacidade de coletar namespaces fora de um determinado Projeto, etc.).
-
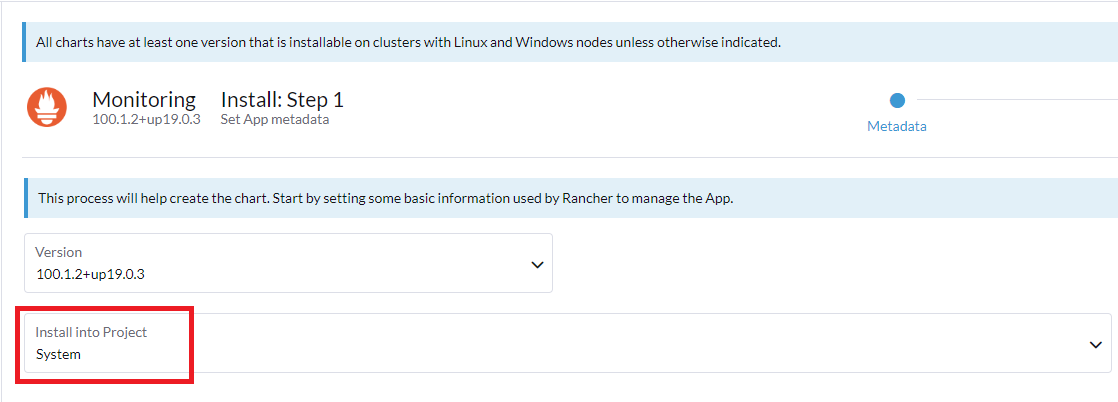
Abra o projeto
Systempara verificar seus namespaces:Clique em na interface do Rancher. Isso exibirá todos os namespaces no projeto
System: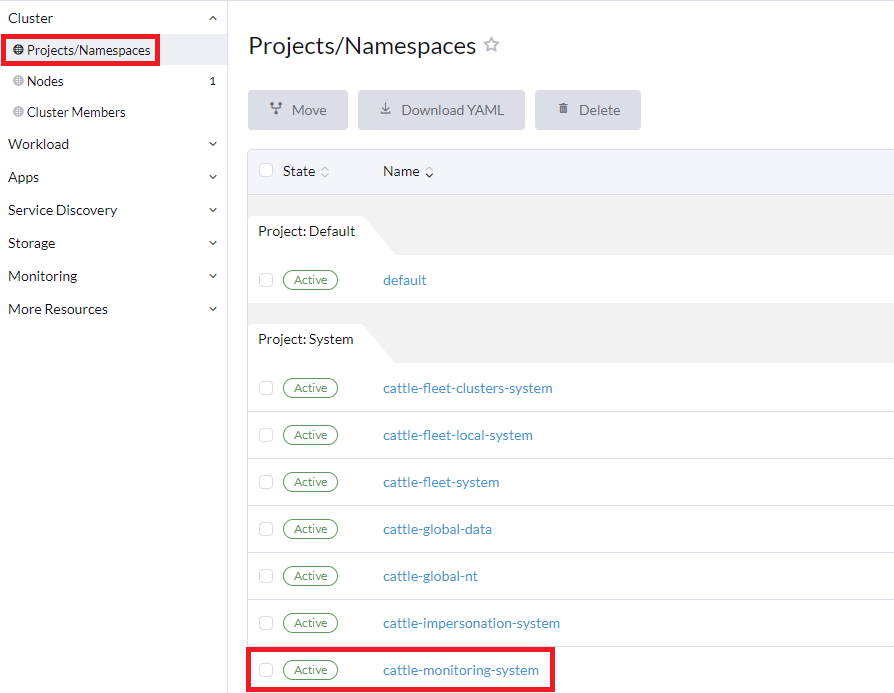
-
Se você tiver uma instalação existente do Monitoring V2 dentro do namespace
cattle-monitoring-system, mas esse namespace não estiver no projetoSystem, você pode mover o namespacecattle-monitoring-systempara o projetoSystemou para outro projeto de acesso limitado. Para fazer isso, você pode optar por:-
Arrastar e soltar o namespace no projeto
Systemou -
Selecionar ⋮ à direita do namespace, clicar em Mover, e então escolher
Systemno menu suspenso Projeto Alvo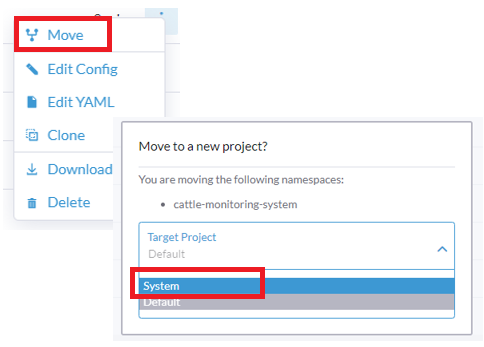
-
Configurar o monitoramento-rancher para observar apenas os recursos criados pelo próprio Helm Chart
Como cada Pilha de Monitoramento de Projeto observará os outros namespaces e coletará métricas ou painéis de carga de trabalho personalizados adicionais, é recomendável configurar as seguintes definições em todos os seletores para garantir que a Pilha Cluster Prometheus monitore apenas os recursos criados pelo próprio Helm Chart:
matchLabels: release: "rancher-monitoring"
Os seguintes campos de seletor são recomendados para ter este valor:
-
.Values.alertmanager.alertmanagerSpec.alertmanagerConfigSelector -
.Values.prometheus.prometheusSpec.serviceMonitorSelector -
.Values.prometheus.prometheusSpec.podMonitorSelector -
.Values.prometheus.prometheusSpec.ruleSelector -
.Values.prometheus.prometheusSpec.probeSelector
Uma vez que esta configuração esteja ativada, você sempre pode criar ServiceMonitors ou PodMonitors que serão capturados pelo Cluster Prometheus adicionando o rótulo release: "rancher-monitoring" a eles, caso em que eles serão ignorados automaticamente pelas Pilhas de Monitoramento de Projeto por padrão, mesmo que o namespace em que esses ServiceMonitors ou PodMonitors residam não sejam namespaces de sistema.
|
Se você não quiser permitir que os usuários criem ServiceMonitors e PodMonitors que se agreguem ao Cluster Prometheus em namespaces de Projeto, você pode definir adicionalmente os namespaceSelectors no chart para direcionar apenas namespaces de sistema (que devem conter |
Aumentar os limites de CPU/memória do Cluster Prometheus
Dependendo da configuração de um cluster, geralmente é recomendável fornecer uma grande quantidade de memória dedicada ao Cluster Prometheus para evitar reinicializações devido a erros de falta de memória (OOMKilled) geralmente causados por churn criado no cluster que gera um grande número de métricas de alta cardinalidade que são geradas e ingeridas pelo Prometheus dentro de um bloco de tempo. Esta é uma das razões pelas quais a pilha de Monitoramento padrão do Rancher espera cerca de 4GB de RAM para poder operar em um cluster de tamanho normal. No entanto, ao introduzir Pilhas de Monitoramento de Projeto que estão todas enviando /federate solicitações para o mesmo Cluster Prometheus e dependem do Cluster Prometheus estar "ativo" para federar esses dados do sistema em seus namespaces, é ainda mais importante que o Cluster Prometheus tenha uma quantidade adequada de CPU/memória atribuída a ele para evitar uma interrupção que pode causar lacunas de dados em todos os Prometheis de Projeto no cluster.
|
Não há recomendações específicas sobre quanta memória o Cluster Prometheus deve ser configurado, pois depende inteiramente da configuração do usuário (nomeadamente a probabilidade de encontrar uma alta taxa de churn e a escala de métricas que poderiam ser geradas naquele momento); geralmente varia por configuração. |
Instalar o Aplicativo Prometheus Federator
-
Clique em ☰ > Gerenciamento de Cluster.
-
Vá para o cluster onde você deseja instalar o Prometheus Federator e clique em Explorar.
-
Clique em Apps -> Charts.
-
Clique no gráfico Prometheus Federator.
-
Clique em Instalar.
-
Na página Metadados, clique em Próximo.
-
No campo Namespaces > ID do Projeto de Liberação do Namespace do Projeto, o
System Projecté usado como padrão, mas pode ser substituído por outro projeto com acesso igualmente limitado. Os IDs dos projetos podem ser encontrados com o seguinte comando executado no cluster upstream local:
kubectl get projects -A -o custom-columns="NAMESPACE":.metadata.namespace,"ID":.metadata.name,"NAME":.spec.displayName-
Clique em Instalar.
Resultado: O Aplicativo Prometheus Federator foi implantado no namespace cattle-monitoring-system.