Activer Prometheus Federator
Configuration requise
Par défaut, Prometheus Federator est configuré et destiné à être déployé aux côtés de rancher-monitoring, qui déploie Prometheus Operator avec un Cluster Prometheus que chaque stack de monitoring de projet est configuré pour fédérer les métriques définies au niveau de l’espace de noms par défaut.
Pour des instructions sur l’installation de rancher-monitoring, référez-vous à cette page.
La configuration par défaut devrait déjà être compatible avec votre stack rancher-monitoring. Cependant, pour optimiser la sécurité et la facilité d’utilisation de Prometheus Federator dans votre cluster, nous recommandons d’apporter ces configurations supplémentaires à rancher-monitoring :
Assurez-vous que l’espace de noms cattle-monitoring-system est placé dans le Projet Système (ou dans un projet similaire, verrouillé, qui a accès aux autres projets du cluster)
Le modèle de sécurité de Prometheus Operator s’attend à ce que l’espace de noms dans lequel il est déployé (par exemple, cattle-monitoring-system) bénéficie d’un accès limité pour toute personne, à l’exception des administrateurs de cluster, afin d’éviter l’escalade de privilèges via l’exécution dans des pods (comme les jobs exécutant des opérations Helm). De plus, déployer Prometheus Federator et tous les stacks Project Prometheus dans le Projet Système garantit que chaque Project Prometheus peut atteindre pour récupérer des charges de travail à travers tous les Projets, même si des Politiques Réseau sont définies via l’Isolation Réseau de Projet. Cela fournit également un accès limité pour les Propriétaires de Projet, les Membres de Projet et d’autres utilisateurs afin qu’ils ne puissent pas accéder à des données auxquelles ils ne devraient pas avoir accès (c’est-à-dire, être autorisés à exécuter dans des pods, configurer la capacité de récupérer des espaces de noms en dehors d’un projet donné, etc.).
-
Ouvrez le projet
Systempour vérifier vos espaces de noms :Cliquez sur dans l’interface utilisateur de Rancher. Cela affichera tous les espaces de noms dans le projet
System: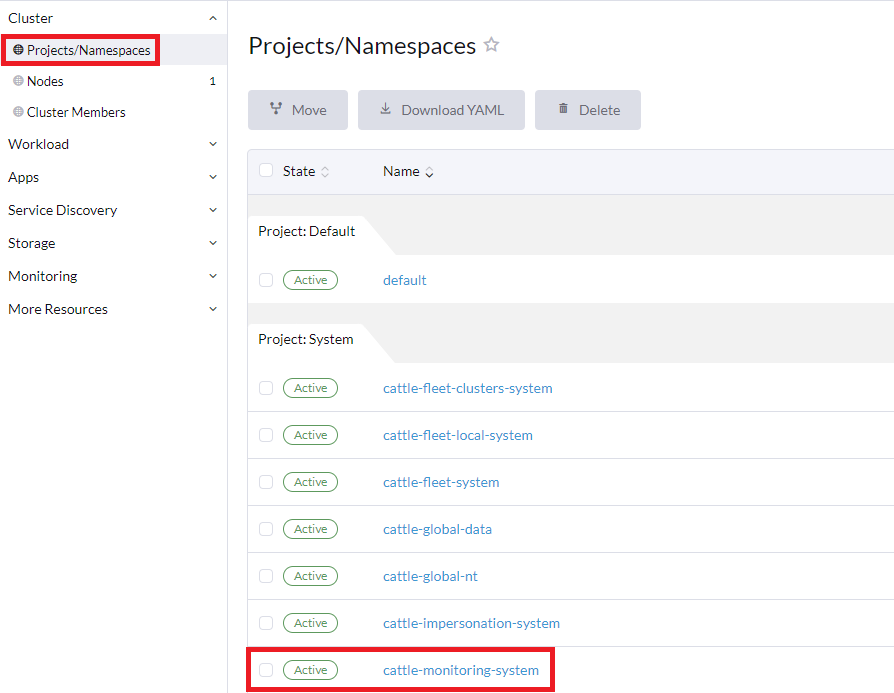
-
Si vous avez une installation Monitoring V2 existante dans l’espace de noms
cattle-monitoring-system, mais que cet espace de noms n’est pas dans le projetSystem, vous pouvez déplacer l’espace de nomscattle-monitoring-systemdans le projetSystemou dans un autre projet à accès limité. Pour ce faire, vous pouvez soit :-
Faites glisser et déposez l’espace de noms dans le projet
Systemou -
Sélectionnez ⋮ à droite de l’espace de noms, cliquez sur Déplacer, puis choisissez
Systemdans le menu déroulant Projet cible :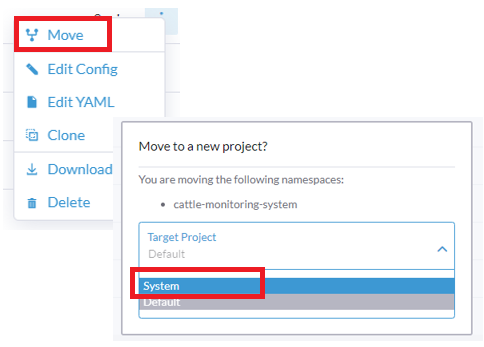
-
Configurez rancher-monitoring pour ne surveiller que les ressources créées par le chart Helm lui-même
Étant donné que chaque pile de surveillance de projet surveillera les autres espaces de noms et collectera, en outre, des métriques de charge de travail personnalisées ou des tableaux de bord supplémentaires, il est recommandé de configurer les paramètres suivants sur tous les sélecteurs afin de garantir que la pile Cluster Prometheus ne surveille que les ressources créées par le chart Helm lui-même :
matchLabels: release: "rancher-monitoring"
Les champs de sélecteur suivants sont recommandés pour avoir cette valeur :
-
.Values.alertmanager.alertmanagerSpec.alertmanagerConfigSelector -
.Values.prometheus.prometheusSpec.serviceMonitorSelector -
.Values.prometheus.prometheusSpec.podMonitorSelector -
.Values.prometheus.prometheusSpec.ruleSelector -
.Values.prometheus.prometheusSpec.probeSelector
Une fois ce paramètre activé, vous pouvez toujours créer des ServiceMonitors ou des PodMonitors qui seront pris en compte par le Cluster Prometheus en ajoutant l’étiquette release: "rancher-monitoring" à ceux-ci, auquel cas ils seront automatiquement ignorés par les piles de surveillance de projet par défaut, même si l’espace de noms dans lequel ces ServiceMonitors ou PodMonitors résident n’est pas un espace de noms système.
|
Si vous ne souhaitez pas permettre aux utilisateurs de créer des ServiceMonitors et des PodMonitors qui s’agrègent dans le Cluster Prometheus dans les espaces de noms de projet, vous pouvez également définir les namespaceSelectors sur le chart pour cibler uniquement les espaces de noms système (qui doivent contenir |
Augmentez les limites de CPU / mémoire du Cluster Prometheus
En fonction de la configuration d’un cluster, il est généralement recommandé de donner une grande quantité de mémoire dédiée au Cluster Prometheus pour éviter les redémarrages dus à des erreurs de mémoire insuffisante (OOMKilled) généralement causées par le churn créé dans le cluster qui entraîne la génération et l’ingestion d’un grand nombre de métriques de haute cardinalité par Prometheus dans un même bloc de temps. C’est l’une des raisons pour lesquelles la pile rancher-monitoring par défaut s’attend à environ 4 Go de RAM pour pouvoir fonctionner dans un cluster de taille normale. Cependant, lors de l’introduction de piles de surveillance de projet qui envoient toutes des requêtes /federate au même Cluster Prometheus et qui dépendent du fait que le Cluster Prometheus soit « en marche » pour fédérer ces données système sur leurs espaces de noms, il est encore plus important que le Cluster Prometheus dispose d’une quantité suffisante de CPU / mémoire qui lui soit attribuée pour éviter une panne pouvant entraîner des lacunes de données dans toutes les piles Project Prometheus du cluster.
|
Il n’y a pas de recommandations spécifiques sur la quantité de mémoire avec laquelle le Cluster Prometheus doit être configuré, car cela dépend entièrement de la configuration de l’utilisateur (à savoir la probabilité de rencontrer un taux de churn élevé et l’échelle des métriques qui pourraient être générées à ce moment-là) ; cela varie généralement selon la configuration. |
Installez l’appli Prometheus Federator
-
Cliquez sur ☰ > Gestion des clusters.
-
Allez dans le cluster où vous souhaitez installer Prometheus Federator et cliquez sur Explorer.
-
Cliquez sur Applis -> Charts.
-
Cliquez sur le Prometheus Federator chart.
-
Cliquez sur Installer.
-
Sur la page Métadonnées, cliquez sur Suivant.
-
Dans le champ Espaces de noms > ID de projet de l’espace de noms de publication de projet, le
System Projectest utilisé par défaut mais peut être remplacé par un autre projet avec un accès également limité. Les identifiants de projet peuvent être trouvés avec la commande suivante exécutée dans le cluster amont local :
kubectl get projects -A -o custom-columns="NAMESPACE":.metadata.namespace,"ID":.metadata.name,"NAME":.spec.displayName-
Cliquez sur Installer.
Résultat : L’appli Prometheus Federator est déployée dans l’espace de noms cattle-monitoring-system.