Architecture de journalisation
Cette section résume l’architecture de l’application de journalisation Rancher.
Pour plus de détails sur le fonctionnement de l’opérateur de journalisation, consultez la documentation officielle.
Comment fonctionne l’opérateur de journalisation
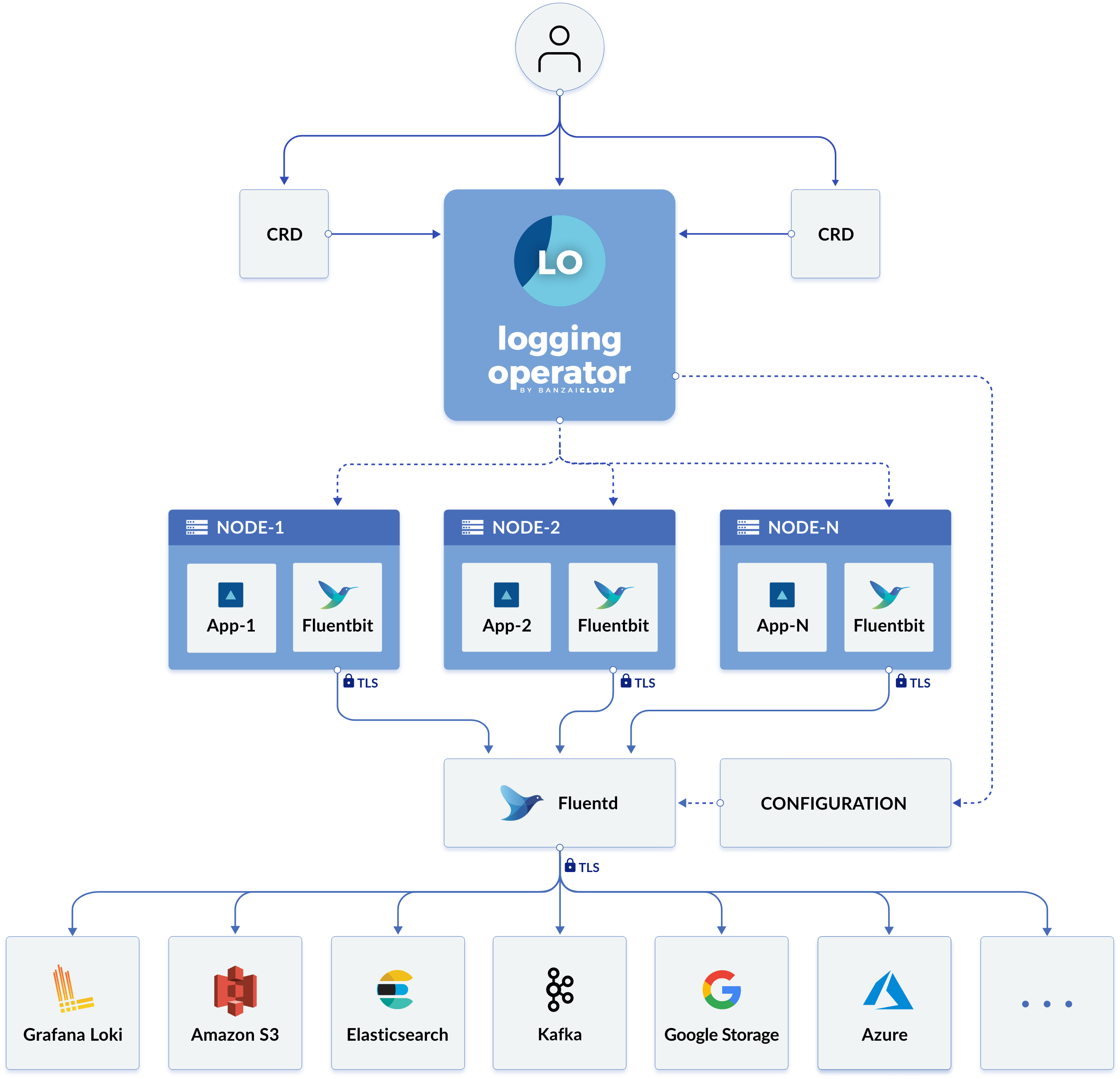
L’opérateur de journalisation automatise le déploiement et la configuration d’un pipeline de journalisation Kubernetes. Il déploie et configure un DaemonSet Fluent Bit sur chaque nœud pour collecter les journaux des conteneurs et des applications à partir du système de fichiers du nœud.
Fluent Bit interroge l’API Kubernetes et enrichit les journaux avec des métadonnées sur les pods, puis transfère à la fois les journaux et les métadonnées à Fluentd. Fluentd reçoit, filtre et transfère les journaux vers plusieurs Outputs.
Les ressources personnalisées suivantes sont utilisées pour définir comment les journaux sont filtrés et envoyés à leur Outputs :
-
Un
Flowest une ressource personnalisée avec un espace de noms qui utilise des filtres et des sélecteurs pour acheminer les messages de journal vers leOutputsapproprié. -
Un
ClusterFlowest utilisé pour acheminer les messages de journal au niveau du cluster. -
Un
Outputest une ressource avec un espace de noms qui définit où les messages de journal sont envoyés. -
Un
ClusterOutputdéfinit unOutputqui est disponible depuis tous lesFlowsetClusterFlows.
Chaque Flow doit référencer un Output, et chaque ClusterFlow doit référencer un ClusterOutput.
La figure suivante tirée de la documentation de l’opérateur de journalisation montre la nouvelle architecture de journalisation :