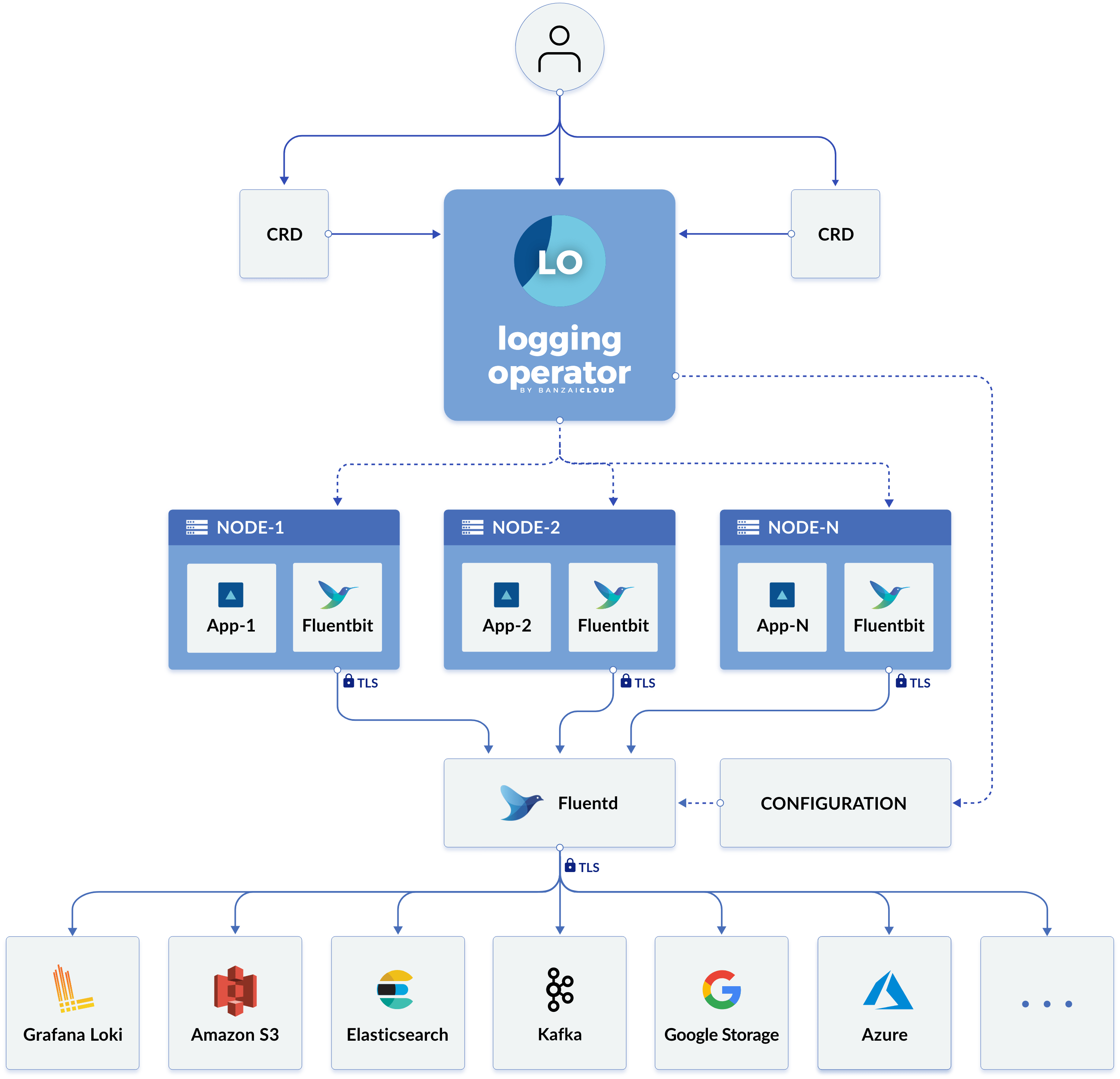
Arquitectura de registro
Esta sección resume la arquitectura de la aplicación de registro de Rancher.
Para más detalles sobre cómo funciona el operador de registro, consulta la documentación oficial.
Cómo funciona el operador de registro
El operador de registro automatiza la ampliación y la configuración de un pipeline de registro en Kubernetes. Despliega y configura un DaemonSet de Fluent Bit en cada nodo para recoger los registros de contenedores y aplicaciones del sistema de archivos del nodo.
Fluent Bit consulta la API de Kubernetes y enriquece los registros con metadatos sobre los pods, y transfiere tanto los registros como los metadatos a Fluentd. Fluentd recibe, filtra y transfiere registros a múltiples Outputs.
Los siguientes recursos personalizados se utilizan para definir cómo se filtran y envían los registros a su Outputs:
-
Un
Flowes un recurso personalizado con espacio de nombres que utiliza filtros y selectores para enrutar mensajes de registro alOutputsapropiado. -
Un
ClusterFlowse utiliza para enrutar mensajes de registro a nivel de clúster. -
Un
Outputes un recurso con espacio de nombres que define a dónde se envían los mensajes de registro. -
Un
ClusterOutputdefine unOutputque está disponible desde todos losFlowsyClusterFlows.
Cada Flow debe hacer referencia a un Output, y cada ClusterFlow debe hacer referencia a un ClusterOutput.
La siguiente figura de la documentación del operador de registro muestra la nueva arquitectura de registro: