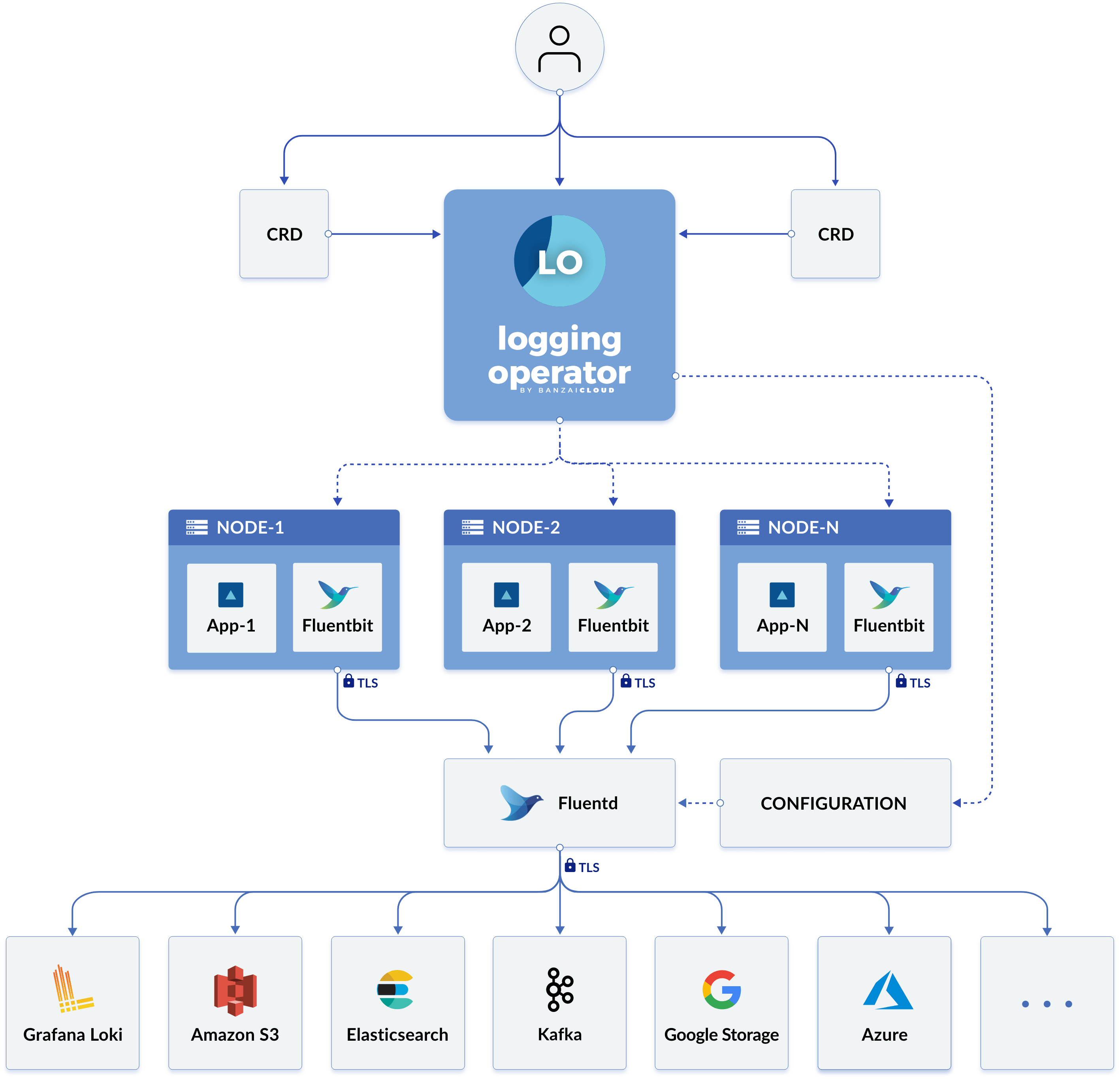
Protokollierungsarchitektur
Dieser Abschnitt fasst die Architektur der Logging-Anwendung von Rancher zusammen.
Für weitere Details zur Funktionsweise des Logging-Operators siehe die offizielle Dokumentation.
Wie der Logging-Operator funktioniert
Der Logging-Operator automatisiert die Implementierung und Konfiguration einer Kubernetes-Logging-Pipeline. Er stellt ein Fluent Bit DaemonSet auf jedem Knoten bereit und konfiguriert es, um Container- und Anwendungs-Logs vom Dateisystem des Knotens zu sammeln.
Fluent Bit fragt die Kubernetes-API ab und bereichert die Protokolle mit Metadaten über die Pods und überträgt sowohl die Protokolle als auch die Metadaten an Fluentd. Fluentd empfängt, filtert und überträgt Protokolle an mehrere Outputs.
Die folgenden benutzerdefinierten Ressourcen werden verwendet, um zu definieren, wie Protokolle gefiltert und an ihre Outputs gesendet werden:
-
Ein
Flowist eine namespaced benutzerdefinierte Ressource, die Filter und Selektoren verwendet, um Protokollnachrichten an die entsprechendenOutputsweiterzuleiten. -
Ein
ClusterFlowwird verwendet, um Protokollnachrichten auf Cluster-Ebene weiterzuleiten. -
Ein
Outputist eine namespaced Ressource, die definiert, wohin die Protokollnachrichten gesendet werden. -
Ein
ClusterOutputdefiniert einOutput, das von allenFlowsundClusterFlowsverfügbar ist.
Jedes Flow muss auf ein Output verweisen, und jedes ClusterFlow muss auf ein ClusterOutput verweisen.
Die folgende Abbildung aus der Dokumentation des Logging-Operators zeigt die neue Protokollierungsarchitektur: