SUSE Rancher Prime Issues
Guest cluster log collection
You can collect guest cluster logs and configuration files. Perform the following steps on each guest cluster node:
-
Log in to the node.
-
Download the Rancher v2.x Linux log collector script and generate a log bundle using the following commands:
curl -OLs https://raw.githubusercontent.com/rancherlabs/support-tools/master/collection/rancher/v2.x/logs-collector/rancher2_logs_collector.sh sudo bash rancher2_logs_collector.sh
The output of the script indicates the location of the generated tarball.
For more information, see The Rancher v2.x Linux log collector script.
Importing of SUSE Virtualization clusters into Rancher
After the cluster-registration-url is set on SUSE Virtualization, a deployment named cattle-system/cattle-cluster-agent is created for importing of the SUSE Virtualization cluster into Rancher.
Import pending due to unable to read CA file error
The following error messages in the cattle-cluster-agent-* pod logs indicate that the SUSE Virtualization cluster cannot be imported into Rancher.
2025-02-13T17:25:22.520593546Z time="2025-02-13T17:25:22Z" level=info msg="Rancher agent version v2.10.2 is starting"
2025-02-13T17:25:22.529886868Z time="2025-02-13T17:25:22Z" level=error msg="unable to read CA file from /etc/kubernetes/ssl/certs/serverca: open /etc/kubernetes/ssl/certs/serverca: no such file or directory"
2025-02-13T17:25:22.529924542Z time="2025-02-13T17:25:22Z" level=error msg="Strict CA verification is enabled but encountered error finding root CA"The root cause is ineffective configuration of Rancher’s agent-tls-mode setting, which controls how Rancher’s agents (cluster-agent, fleet-agent, and system-agent) validate Rancher’s certificate when establishing a connection. The default value of this setting depends on the Rancher version and installation type.
| Type | Versions | Default Value |
|---|---|---|
New installation |
v2.8 |
|
New installation |
v2.9 and later |
|
Upgrade |
v2.8 to v2.9 |
|
You can configure this setting to match your requirements by performing the following steps:
-
Log in to the Rancher UI.
-
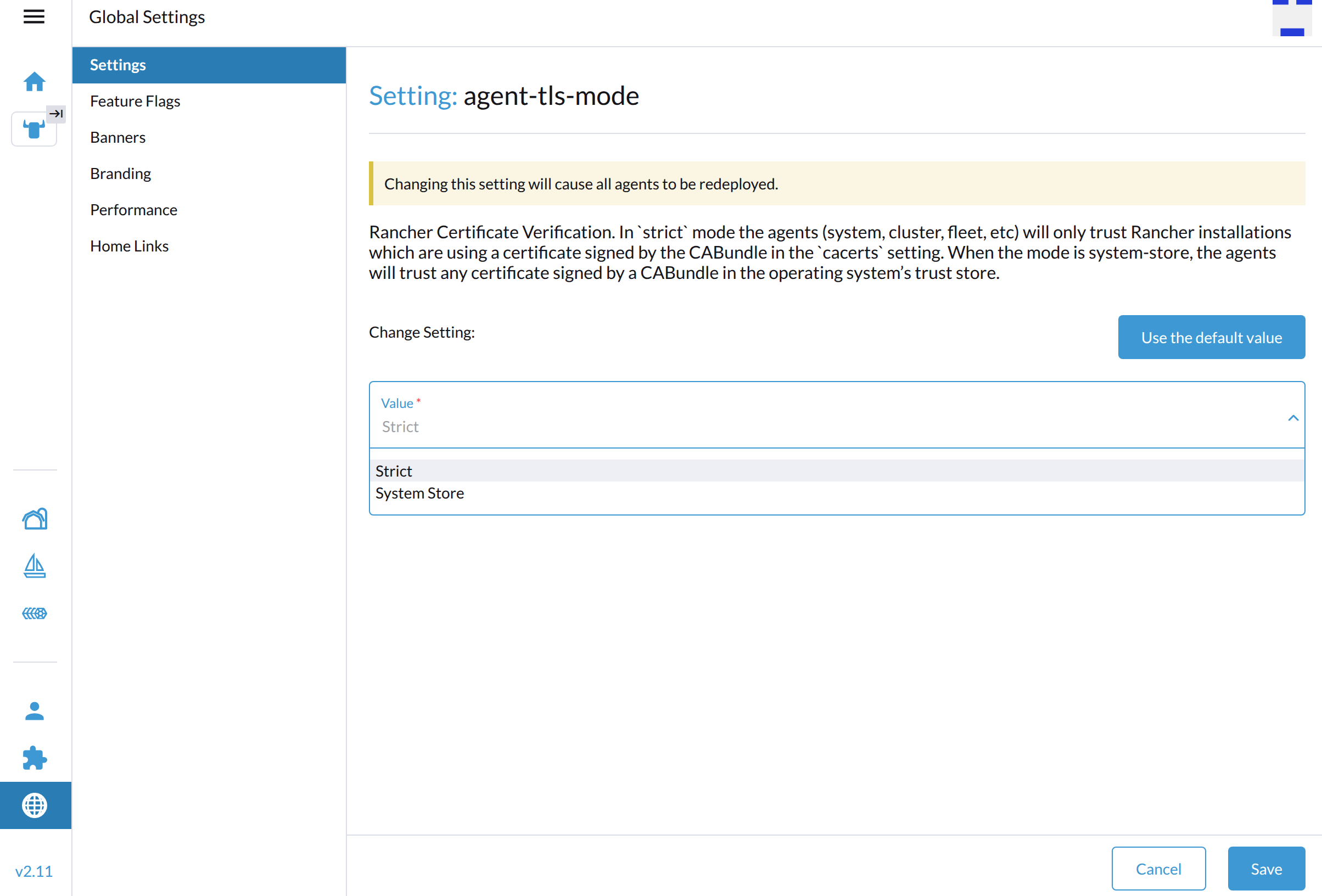
Go to Global Settings → Settings.
-
Select agent-tls-mode, and then select ⋮ → Edit Setting to access the configuration options.
-
Select one of the following values:
-
Strict: Rancher’s agents only trust certificates generated by the Certificate Authority (CA) specified in the
cacertssetting. This is the recommended default TLS setting.The Strict option enables a higher level of security by requiring Rancher to have access to the CA that generated the certificate visible to the agents. In the case of certain certificate configurations (notably, external certificates), this is not automatic, and extra configuration is required. For more information about scenarios that require extra configuration, see Choose your SSL Configuration in the Rancher documentation.
-
System Store: Rancher’s agents trust any certificate generated by a public CA specified in the operating system’s trust store. Use this setting if your setup uses an external trust authority and you don’t have ownership over the Certificate Authority.
Using the System Store setting implies that the agent trusts all external authorities found in the operating system’s trust store including those outside of the user’s control.
-
-
Click Save.
Related issues:
-
Rancher: #45628 (See this comment.)
Guest cluster load balancer IP is not reachable
Issue description
The load balancer service successfully obtains an IP address from the DHCP server or IP pool but remains inaccessible.
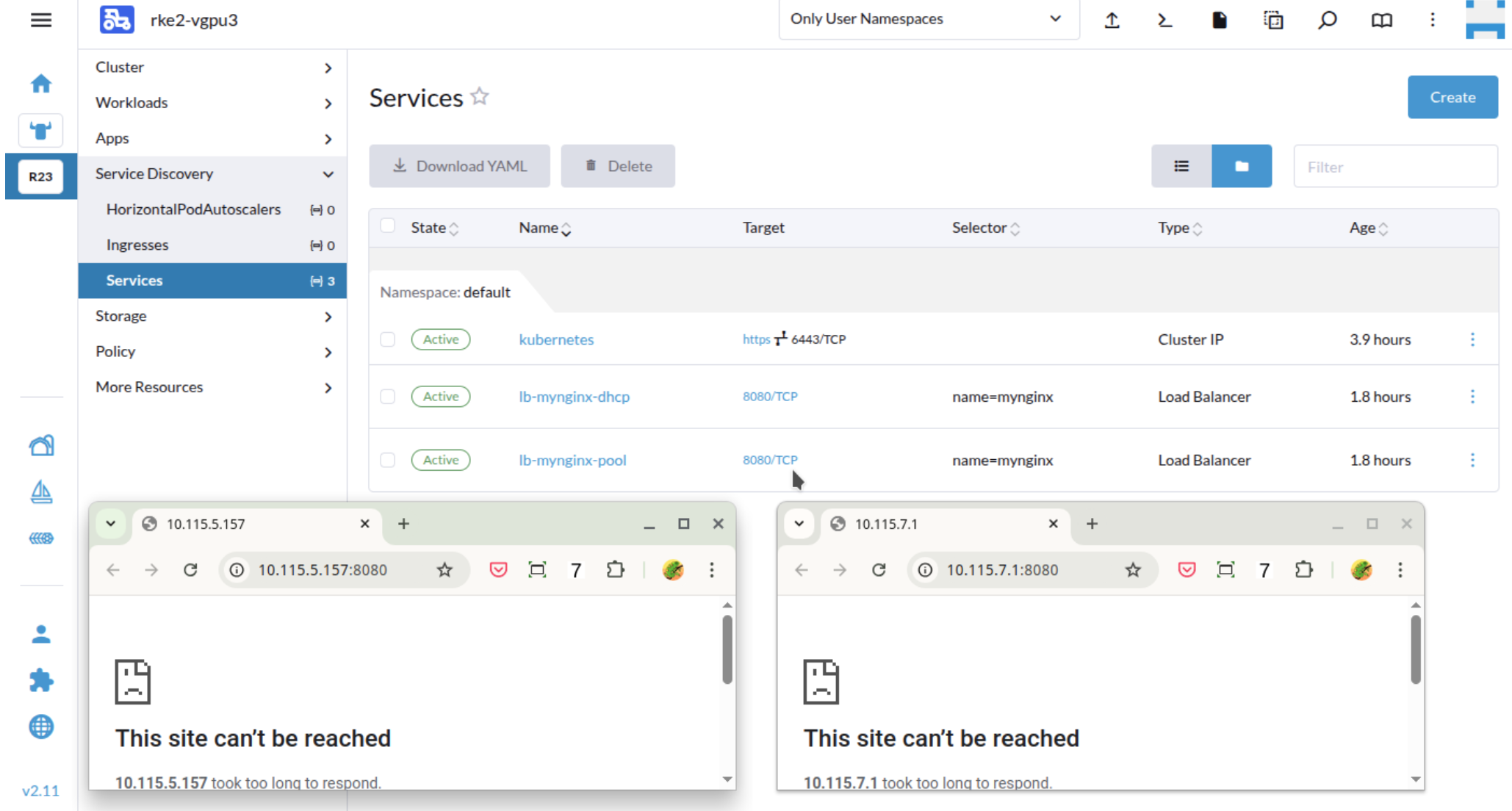
To check if the issue exists in your environment, perform the following steps:
-
Create a new guest cluster with the following settings:
-
Container Network: "Calico"
-
Cloud Provider: "Harvester"
-
-
Deploy NGINX on the new guest cluster.
kubectl apply -f https://k8s.io/examples/application/deployment.yaml -
Create a load balancer that uses NGINX.
Root cause
In the following example, a guest cluster node uses the IP address 10.115.1.46 and a new load balancer is assigned the IP address 10.115.6.200. When this load balancer’s IP address is later added to a new interface, such as vip-fd8c28ce (attached to @enp1s0), the Calico controller takes over the load balancer IP address. This conflict causes the load balancer IP address to become unreachable from outside the cluster.
To verify the cause, run the following command on the affected guest cluster node:
ip -d link show dev vxlan.calico
44: vxlan.calico: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 66:a7:41:00:1d:ba brd ff:ff:ff:ff:ff:ff promiscuity 0 allmulti 0 minmtu 68 maxmtu 65535
info: Using default fan map value (33)
vxlan id 4096 local 10.115.6.200 dev vip-8a928fa0 srcport 0 0 dstport 4789 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 tso_max_size 65536 tso_max_segs 65535 gro_max_size 65536
The IP 10.115.6.200 is from the vip-* interface.Affected Versions
The IP auto-detection feature is available in Calico v3.22 and other versions, with first-found as the default value.
Consequently, most RKE2 clusters using Calico as the default CNI alongside the Harvester Cloud Provider to deliver load balancer services are susceptible to this issue.
Workaround
Newly created clusters
When creating a new cluster in Rancher, select Add-on: Calico to open the YAML configuration window. Add nodeAddressAutodetectionV4 and skipInterface: vip.* to the spec.installation.calicoNetwork field.
installation:
backend: VXLAN
calicoNetwork:
bgp: Disabled
nodeAddressAutodetectionV4: (1)
skipInterface: vip.* (2)| 1 | Configures IPv4 address auto-detection filtering. |
| 2 | Instructs the Calico controller to skip any interfaces matching the vip.* naming pattern. |
These additional lines ensure that the Calico controller does not inadvertently intercept the assigned load balancer IP addresses.
Existing clusters
-
Run the command
kubectl edit installation. -
Go to the
spec.calicoNetwork.nodeAddressAutodetectionV4block and apply the following changes:-
Remove the
firstFound: trueentry if it is present. -
Add the
skipInterface: vip.*parameter.
-
-
Save the changes.
-
Monitor the cluster for approximately two minutes while the
calico-system/calico-nodeDaemonSet undergoes a rolling update.The newly initialized pods automatically use the node IP for the VXLAN.
-
Check if the
vxlan.calicointerface uses the node IP (such as10.115.1.46) instead of the VIP.ip -d link show dev vxlan.calico 45: vxlan.calico: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/ether 66:a7:41:00:1d:ba brd ff:ff:ff:ff:ff:ff promiscuity 0 allmulti 0 minmtu 68 maxmtu 65535 info: Using default fan map value (33) vxlan id 4096 local 10.115.1.46 dev enp1s0 srcport 0 0 dstport 4789 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 tso_max_size 65536 tso_max_segs 65535 gro_max_size 65536 -
If the
vxlan.calicointerface still uses the VIP, check thetigera-operatorpod logs for the key phrasefailed calling webhook.kubectl -n tigera-operator logs tigera-operator-8566d6db5c-wfjkt ... {"level":"error","ts":"2025-12-18T09:06:37Z","msg":"Reconciler error","controller":"tigera-installation-controller","object":{"name":"periodic-5m0s-reconcile-event"},"namespace":"","name":"periodic-5m0s-reconcile-event","reconcileID":"bae9d2da-a4bf-4d8b-89b8-c8a23a96f351","error":"Internal error occurred: failed calling webhook \"rancher.cattle.io.namespaces\": failed to call webhook: Post \"https://rancher-webhook.cattle-system.svc:443/v1/webhook/validation/namespaces?timeout=10s\": context deadline exceeded"...}If this error occurs, add the following container parameters directly to the
calico-system/calico-nodeDaemonSet.- name: IP_AUTODETECTION_METHOD value: skip-interface=vip.* -
Check the
vxlan.calicointerface again after a few minutes.Once the interface stops using the VIP, the VIP will become reachable.
Guest cluster provisioning is stuck at waiting for cluster agent to connect
Affected versions
-
Rancher: v2.14.0
-
RKE2: v1.34.x, v1.35.1, v1.35.2, v1.35.3
-
SUSE Virtualization: v1.8.0
This issue frequently affects environments running Rancher v2.14.0, RKE2 v1.35.2 or v1.35.3, and SUSE Virtualization v1.8.0.
Although these specific releases are most affected, the bug can also affect other version combinations. Check if the symptoms exist in your cluster, and view the related GitHub issue for more details.
Issue description
-
Import the SUSE Virtualization cluster into Rancher.
-
Create a new guest cluster using the Harvester Node Driver with the default Harvester Cloud Provider.
-
On the Rancher UI, you will see the cluster state switch to
Updatingalongside a message such as`…waiting for cluster agent to connect.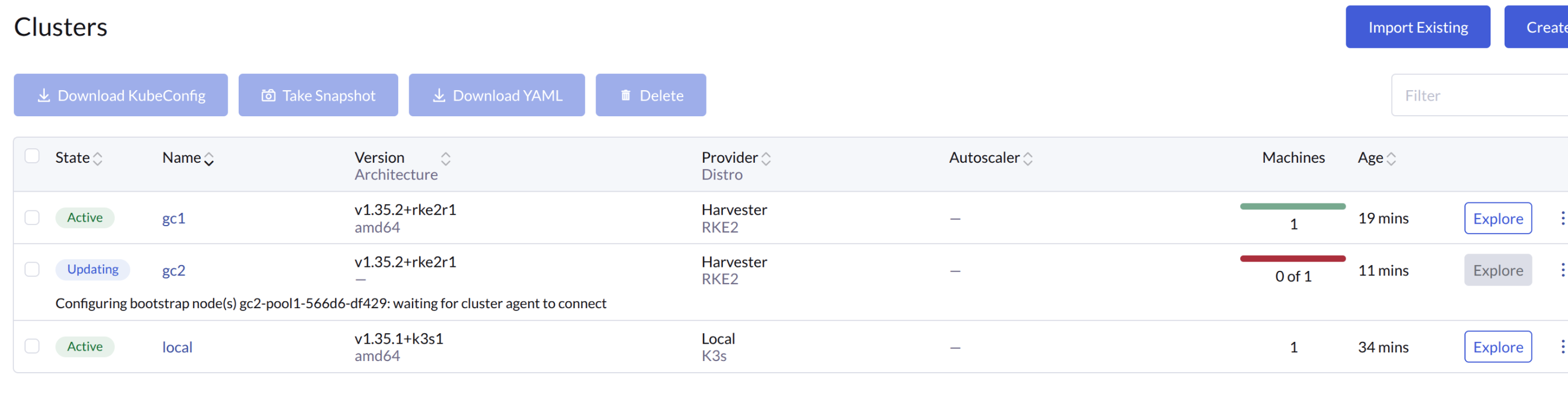
-
Check the running pods.
kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE calico-system calico-kube-controllers-76456b5c58-xgzmn 0/1 Pending 0 29m calico-system calico-node-n6ptz 0/1 Running 0 29m calico-system calico-typha-5b6744bd87-vfzpm 0/1 Pending 0 29m cattle-system cattle-cluster-agent-66f658c49f-mm4xr 0/1 Pending 0 29m kube-system etcd-rke2-v1352-7-pool1-wf5n2-8ng58 1/1 Running 0 30m kube-system helm-install-harvester-csi-driver-h8tqb 0/1 CrashLoopBackOff 10 (3m24s ago) 29m kube-system helm-install-rke2-calico-5t6hj 0/1 Completed 2 29m kube-system helm-install-rke2-calico-crd-spg62 0/1 Completed 0 29m kube-system helm-install-rke2-coredns-nx5rl 0/1 Completed 0 29m kube-system helm-install-rke2-metrics-server-tw8xj 0/1 Pending 0 29m kube-system helm-install-rke2-runtimeclasses-csqgq 0/1 Pending 0 29m kube-system helm-install-rke2-snapshot-controller-crd-dwkbt 0/1 Pending 0 29m kube-system helm-install-rke2-snapshot-controller-d2crg 0/1 Pending 0 29m kube-system helm-install-rke2-traefik-crd-bqb6g 0/1 Pending 0 29m kube-system helm-install-rke2-traefik-fnjwg 0/1 Pending 0 29m kube-system kube-apiserver-rke2-v1352-7-pool1-wf5n2-8ng58 1/1 Running 0 30m kube-system kube-controller-manager-rke2-v1352-7-pool1-wf5n2-8ng58 1/1 Running 0 30m kube-system kube-proxy-rke2-v1352-7-pool1-wf5n2-8ng58 1/1 Running 0 30m kube-system kube-scheduler-rke2-v1352-7-pool1-wf5n2-8ng58 1/1 Running 0 30m kube-system rke2-coredns-rke2-coredns-5d4dd4bdd9-5tcdm 0/1 Pending 0 29m kube-system rke2-coredns-rke2-coredns-autoscaler-67b9856946-m44cd 0/1 Pending 0 29m tigera-operator tigera-operator-6db5b6cfd8-gxhfv 1/1 Running 0 29mkubectl describe pod -n calico-system calico-typha-5b6744bd87-vfzpm Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 34m default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling. Warning FailedScheduling 9m12s (x5 over 29m) default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.Treat failing stuck pods as symptoms. The root cause is that the cloud provider has not yet updated the corresponding
nodeobject. -
Check the node object.
kubectl get node <node-name> -o yaml... spec: ... taints: - effect: NoSchedule key: node.cloudprovider.kubernetes.io/uninitialized value: "true"If the node has a
node.cloudprovider.kubernetes.io/uninitialized:NoScheduletaint, this indicates that the cloud provider has not initialized the node. -
Retrieve the description of the
helm-install-harvester-cloud-providerjob in thekube-systemnamespace.kubectl describe job -n kube-system helm-install-harvester-cloud-provider ... Name: helm-install-harvester-cloud-provider Namespace: kube-system ... Completion Mode: NonIndexed Suspend: false Backoff Limit: 1000 Start Time: Tue, 31 Mar 2026 12:49:15 +0000 Pods Statuses: 0 Active (0 Ready) / 0 Succeeded / 0 Failed ...The
harvester-cloud-providerjob appears stalled. The pod count in thePods Statusfield remains at0 Active (0 Ready) / 0 Succeeded / 0 Faileddespite the job having started.
Root cause
A race condition during the RKE2 bootstrap stage causes the helm-install-harvester-cloud-provider pod to encounter a rapid create, delete, create loop. This cycling desynchronizes the job controller, stalling the job and preventing it from updating the node object.
kube-system-kube-controller-manager log:
...
[job_controller.go:659] "Unhandled Error" err="syncing job: tracking status: adding uncounted pods to status:
Operation cannot be fulfilled on jobs.batch \"helm-install-harvester-cloud-provider\":
StorageError: invalid object, Code: 4, Key: /registry/jobs/kube-system/helm-install-harvester-cloud-provider,
ResourceVersion: 0, AdditionalErrorMsg: Precondition failed: UID in precondition: 6ae0b0b2-34c6-42e2-afc9-d7616ec93f2e,
UID in object meta: 8515b052-3a07-43e8-bf01-d898e2b9c27c" logger="UnhandledError"|
The UID mismatch in the An upstream fix for this race condition is under development and will be included in upcoming releases. |
Resolution
This issue is resolved in RKE2 v1.35.4 and all subsequent releases.
RKE2 v1.35.4 is available by default starting with Rancher v2.14.1. Refer to the Rancher documentation for information about upgrading Rancher and its guest clusters. SUSE Virtualization requires no changes or upgrades to resolve this issue.
Workaround
-
Manually delete the stalled job to force the controller to recreate it.
kubectl delete job -n kube-system helm-install-harvester-cloud-provider job.batch "helm-install-harvester-cloud-provider" deleted from kube-system namespaceA new job will be created within a few minutes.
-
Check if the
uninitializedtaint has been dropped.kubectl get nodes -o jsonpath='{.items[*].spec.taints}'Once the job is recreated successfully, querying the node taints will return an empty response. This allows the pending pods to be scheduled. The guest cluster will automatically recover.
-
Reprovision the failed cluster.