|
Esta es documentación inédita para SUSE® Storage 1.12 (Dev). |
Volúmenes ReadWriteMany (RWX)
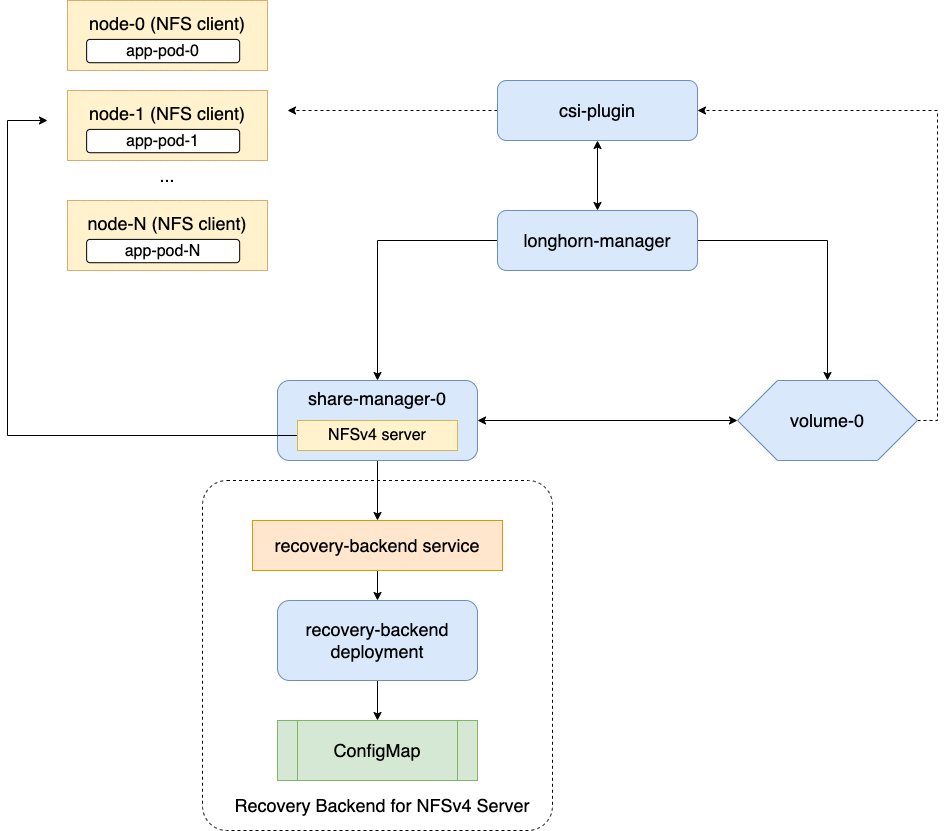
SUSE Storage soporta volúmenes ReadWriteMany (RWX) exponiendo volúmenes Longhorn regulares a través de servidores NFSv4 que residen en pods de gestor de recursos compartidos.
Introducción
SUSE Storage proporciona dos tipos de volúmenes RWX, cada uno optimizado para diferentes requisitos de carga de trabajo:
Volúmenes RWX genéricos (no migrables)
Volúmenes RWX genéricos proporcionan acceso a un sistema de archivos compartido a través de múltiples nodos. Utilizan servidores NFSv4.1 dedicados que se ejecutan en Pods de share-manager-<volume-name> dentro del espacio de nombres longhorn-system. Cada volumen RWX está emparejado con un Servicio correspondiente que expone el punto final NFS a los clientes.
Estos volúmenes son ideales para cargas de trabajo que necesitan acceso concurrente a archivos pero no soportan migración en vivo. La migración en vivo es el proceso de mover una carga de trabajo en ejecución de un host de origen a un host de destino sin interrupción del servicio. Durante la migración, los volúmenes son accesibles solo desde la carga de trabajo de origen. Una vez completada, la carga de trabajo de destino toma el control del acceso, y la carga de trabajo de origen se termina.
Características
-
No capaz de migración en vivo.
-
Utiliza NFSv4.1 para compartir mediante un sistema de archivos.
-
Adecuado para almacenamiento compartido general y cargas de trabajo de acceso a archivos en múltiples nodos.
|
Aviso: Actualizaciones diferidas de la imagen del Pod del gestor de recursos compartidos en volúmenes RWX activos Tras una actualización del sistema Longhorn, cuando un volumen RWX genérico (no migrable) permanece adjunto, las modificaciones al |
Volúmenes RWX migrables
Los volúmenes RWX migrables están diseñados específicamente para cargas de trabajo virtualizadas como las máquinas virtuales de KubeVirt que requieren [migración en vivo](https://kubevirt.io/user-guide/compute/live_migration/) mientras mantienen las operaciones de E/S en curso. Estos volúmenes permiten el movimiento sin interrupciones de las máquinas virtuales entre nodos durante operaciones de mantenimiento, conmutación por error o reequilibrio sin interrupción del servicio.
Características
-
Diseñados para escenarios de migración en vivo.
-
Requieren
volumeMode: Block(no se admite el modoFilesystem). -
Requieren el modo de acceso ReadWriteMany y una StorageClass con
migratable: "true"(que establecevolume.spec.migratable=trueen el volumen de Longhorn). -
No están destinados a cargas de trabajo de sistemas de archivos compartidos generales.
|
Puedes distinguir los volúmenes RWX migrables comprobando el campo |
Requisitos para volúmenes RWX genéricos (no migrables)
-
Cada nodo cliente NFS necesita tener un cliente NFSv4 instalado.
Por favor, consulta Instalación del cliente NFSv4 para más detalles sobre la instalación.
Solución de problemas:Si el cliente NFSv4 no está disponible en el nodo, intentar montar el volumen resulta en un mensaje de error que incluye el siguiente texto:
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
-
El nombre de host de cada nodo es único en el clúster de Kubernetes.
Hay un servicio de recuperación backend dedicado para servidores NFS en el sistema Longhorn. Cuando un cliente se conecta a un servidor NFS, la información del cliente, incluido su nombre de host, se almacenará en el backend de recuperación. Cuando un Pod del gestor de recursos compartidos o un servidor NFS se termina de manera anormal, SUSE Storage creará uno nuevo. Dentro del período de gracia de 90 segundos, los clientes recuperarán los bloqueos utilizando la información del cliente almacenada en el backend de recuperación.
Creación y uso de volúmenes RWX genéricos (no migrables)
|
Un volumen RWX debe tener el modo de acceso configurado en |
-
Para los volúmenes Longhorn provisionados dinámicamente, el modo de acceso se basa en el modo de acceso del PVC.
-
Para los volúmenes Longhorn creados manualmente (restaurar, volumen de DR), el modo de acceso se puede especificar durante la creación en la SUSE Storage interfaz de usuario.
-
Al crear un PV/PVC para un volumen Longhorn a través de la interfaz de usuario, el modo de acceso del PV/PVC se basará en el modo de acceso del volumen.
-
Se puede cambiar el modo de acceso del volumen Longhorn a través de la interfaz de usuario si el volumen no está vinculado a un PVC.
-
Para un volumen Longhorn que es utilizado por un PVC RWX, el modo de acceso del volumen se cambiará a RWX.
Configuración de la localidad del volumen para volúmenes RWX genéricos (no migrables)
SUSE Storage proporciona nuevas configuraciones que te permiten controlar con precisión la localidad de datos de los volúmenes RWX (a través de la identificación de los pods del gestor de recursos compartidos asociados). Estas configuraciones granulares funcionan con configuraciones globales relacionadas para proporcionar un rendimiento óptimo, resiliencia y cumplimiento de políticas o restricciones organizativas.
shareManagerNodeSelector
Puedes usar el parámetro StorageClass shareManagerNodeSelector para especificar selectores para identificar nodos en los que se pueden programar los volúmenes RWX. Estos selectores se fusionan con las configuraciones globales system-managed-components-node-selector y luego se aplican a los pods del gestor de recursos compartidos de los volúmenes RWX para proporcionar un mayor control sobre la localidad del volumen.
Ejemplo:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerNodeSelector: label-key1:label-value1;label-key2:label-value2
En este ejemplo, los volúmenes RWX provisionados con el StorageClass especificado se programarán en nodos con las etiquetas label-key1:label-value1 y label-key2:label-value2.
allowedTopologies
Longhorn convierte las configuraciones storageClass.allowedTopologies en reglas de afinidad para los pods del gestor de recursos compartidos de los volúmenes RWX. Esto asegura que los pods se programen en nodos que cumplan con los requisitos topológicos especificados (como regiones y zonas) y se alineen con la localidad del volumen RWX.
Ejemplo:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/region
values:
- us-west-1
En este ejemplo, los pods del gestor de recursos compartidos y los volúmenes RWX se programarán en la us-west-1 región.
shareManagerTolerations
También puedes usar el parámetro StorageClass shareManagerTolerations para permitir una programación más flexible basada en los taints de los nodos. Las toleraciones definidas se fusionan con los ajustes globales taint-toleration y luego se aplican a los pods del gestor de recursos compartidos.
Ejemplo:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerTolerations: nodetype=storage:NoSchedule
En este ejemplo, los pods del gestor de recursos compartidos tolerarán el nodetype=storage:NoSchedule taint en los nodos, permitiendo que se programen en esos nodos.
Configurando las opciones de montaje de volumen para volúmenes RWX genéricos (no migrables)
Un volumen RWX es accesible solo cuando se monta a través de NFS. Por defecto, SUSE Storage utiliza la versión 4.1 de NFS con la opción de montaje softerr, un valor timeo de "600", y un valor retrans de "5".
Si el servidor NFS se vuelve inaccesible, las solicitudes de los clientes NFS se reintentan de acuerdo con el valor retrans configurado. Eventos de mayor duración, como cortes de energía y factores como particiones de red, hacen que las solicitudes eventualmente fallen. Se devuelve un error de NFS (ETIMEDOUT para la opción de montaje softerr) a la aplicación que llama y puede ocurrir pérdida de datos. Si softerr no es compatible, SUSE Storage utiliza automáticamente la opción de montaje soft en su lugar, que devuelve un EIO como error.
Puedes utilizar opciones de montaje específicas para nuevos volúmenes. Primero, crea una StorageClass personalizada con un parámetro nfsOptions, y luego crea PVCs para volúmenes RWX utilizando esa StorageClass específica.
Ejemplo:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880"
fromBackup: ""
fsType: "ext4"
nfsOptions: "vers=4.2,noresvport,softerr,timeo=600,retrans=5"|
Para crear PVCs para volúmenes RWX utilizando la StorageClass de muestra, reemplaza la cadena |
Notas
-
Debes proporcionar el conjunto completo de opciones deseadas. Cualquier opción no suministrada utilizará los valores predeterminados del lado del servidor NFS, no los propios de SUSE Storage.
-
SUSE Storage no valida la cadena
nfsOptions, por lo que los valores erróneos y los errores tipográficos no se señalan. Cuando la cadena es inválida, el montaje es rechazado por el servidor NFS y el volumen no se crea ni se adjunta. -
En SUSE Storage v1.4.0 a 1.4.3 y v1.5.0 a v1.5.1, los volúmenes dentro de un pod del gestor de recursos compartidos (específicamente, en el paso
NodeStageVolume) se montan de forma rígida por defecto mediante el plugin Longhorn CSI. El montaje rígido permite que SUSE Storage reintente persistentemente enviar solicitudes NFS, asegurando que las IOs no fallen incluso cuando el servidor NFS se vuelve inaccesible durante algún tiempo. Las IOs se reanudan sin problemas cuando el servidor recupera la conectividad o se crea un servidor de reemplazo.Este mecanismo para garantizar la integridad de los datos, sin embargo, conlleva cierto riesgo. Para mantener la estabilidad, el kernel de Linux no permite desmontar un sistema de archivos hasta que se completen todas las IOs pendientes. Esto es una preocupación porque el sistema no puede apagarse hasta que todos los sistemas de archivos estén desmontados. Si el servidor NFS no puede recuperarse, los nodos cliente deben someterse a un reinicio forzado.
Para mitigar el problema, actualiza la versión a v1.4.4, v1.5.2 o una versión posterior. Después de actualizar, se aplica automáticamente
softerrosoftal parámetronfsOptionscada vez que se vuelven a adjuntar volúmenes RWX (si no se sobrescriben los ajustes predeterminados). -
Aún puedes utilizar la opción de montaje
hard(a través del mecanismo de sobrescrituranfsOptions), pero los volúmenes montados de forma rígida están sujetos a los riesgos descritos.
Para obtener más información, consulta #6655.
Manejo de fallos para volúmenes RWX genéricos (no migrables)
-
El Pod share-manager se termina de forma anormal
La entrada/salida del cliente estará bloqueada hasta que SUSE Storage cree un nuevo Pod share-manager y el volumen asociado. Una vez que el Pod se crea con éxito, comienza el período de gracia de 90 segundos para la recuperación de bloqueos, y los usuarios esperarían
-
Antes de que finalice el período de gracia, la entrada/salida del cliente al volumen RWX seguirá estando bloqueada.
-
El servidor rechaza las operaciones de LECTURA y ESCRITURA y las solicitudes de bloqueo no recuperables con un error de NFS4ERR_GRACE.
-
El período de gracia puede finalizarse anticipadamente si todos los bloqueos se recuperan con éxito.
Después de salir del período de gracia, las entradas/salidas de los clientes que recuperan con éxito los bloqueos continúan sin errores de identificador de archivo obsoleto ni errores de entrada/salida. Si un bloqueo no puede recuperarse dentro del período de gracia, el bloqueo se descarta y el servidor devuelve un error de entrada/salida al cliente. El cliente restablece un nuevo bloqueo. La aplicación debe manejar el error de entrada/salida. Sin embargo, no todas las aplicaciones pueden manejar errores de entrada/salida debido a su implementación. Por lo tanto, puede resultar en el fallo de la operación de entrada/salida y la pérdida de datos. La consistencia de los datos puede ser un problema.
+ Aquí hay un ejemplo de un DaemonSet utilizando un volumen RWX.
+ Cada Pod del DaemonSet está escribiendo datos en el volumen RWX. Si el nodo donde se está ejecutando el Pod share-manager falla, se crea un nuevo Pod share-manager en otro nodo. Dado que uno de los clientes ubicados en el nodo caído ha desaparecido, el proceso de recuperación del bloqueo no puede finalizarse antes del período de gracia de 90 segundos, aunque los bloqueos de los clientes restantes se han recuperado con éxito. Las operaciones de entrada/salida de estos clientes continúan después de que el período de gracia ha expirado.
-
-
Si el servicio DNS de Kubernetes falla, los Pods share-manager no podrán comunicarse con longhorn-nfs-recovery-backend.
El servidor NFS-ganesha en un Pod share-manager se comunica con
longhorn-nfs-recovery-backenda través de la IP del serviciolonghorn-recovery-backend. Si el servicio DNS está fuera de servicio, la creación y eliminación de volúmenes RWX, así como la recuperación de servidores NFS, serán inoperables. Por lo tanto, se recomienda una alta disponibilidad del servicio DNS para evitar fallos en la comunicación. -
Función de conmutación por error rápida.
SUSE Storage admite una función que puede mejorar la disponibilidad al acortar el tiempo que se tarda en recuperarse de un fallo del nodo en el que se está ejecutando el Pod share-manager del servidor NFS del volumen. La función utiliza una pulsación directa para supervisar el servidor. Si el servidor no responde, actúa para crear uno nuevo más rápido que la secuencia habitual. También configura el servidor NFS de manera diferente, para acortar el período de gracia de recuperación de 90 a 30 segundos.
Más detalles están en RWX Volume Fast Failover.
Migración desde el Proveedor Externo Anterior.
El PVC a continuación crea un trabajo de Kubernetes que puede copiar datos de un volumen a otro.
-
Reemplaza el
data-source-pvccon el nombre del PVC RWX NFSv4 anterior que fue creado por Kubernetes. -
Reemplaza el
data-target-pvccon el nombre del nuevo PVC RWX que deseas utilizar para tus nuevas cargas de trabajo.
Puedes crear manualmente un nuevo volumen RWX Longhorn + PVC/PV, o simplemente crear un PVC RWX y luego hacer que Longhorn aprovisione dinámicamente un volumen para ti.
Ambos PVCs deben existir en el mismo espacio de nombres. Si estabas utilizando un espacio de nombres diferente al predeterminado, cambia el espacio de nombres del trabajo a continuación.
apiVersion: batch/v1
kind: Job
metadata:
namespace: default # namespace where the PVC's exist
name: volume-migration
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: data-source-pvc # change to data source PVC
- name: new-vol
persistentVolumeClaim:
claimName: data-target-pvc # change to data target PVC