Arquitetura e Conceitos
SUSE Storage cria um controlador de armazenamento dedicado para cada volume e replica o volume de forma síncrona em várias réplicas armazenadas em vários nós.
O controlador de armazenamento e as réplicas são orquestrados usando o Kubernetes.
Para uma visão geral das funcionalidades, consulte esta seção.
Para os requisitos de instalação, acesse esta seção.
Esta seção assume familiaridade com os conceitos de armazenamento persistente do Kubernetes. Para mais informações sobre esses conceitos, consulte o apêndice. Para ajuda com a terminologia usada nesta página, consulte esta seção.
1. Design
O design possui duas camadas: o plano de dados e o plano de controle. O Longhorn Engine é um controlador de armazenamento que corresponde ao plano de dados, e o Longhorn Manager corresponde ao plano de controle.
1.1. O Longhorn Manager e o Longhorn Engine
O Pod do Longhorn Manager é executado em cada nó no SUSE Storage cluster como um DaemonSet do Kubernetes. Ele cria e gerencia volumes no cluster Kubernetes e lida com as chamadas de API da SUSE Storage interface do usuário ou do plugin Longhorn CSI. Ele segue o padrão de controlador do Kubernetes, que às vezes é chamado de padrão operador.
O Longhorn Manager se comunica com o servidor de API do Kubernetes para criar um novo SUSE Storage volume CR. Então, o Longhorn Manager observa a resposta do servidor de API, e quando vê que o servidor de API do Kubernetes criou um novo SUSE Storage volume CR, o Longhorn Manager cria um novo volume.
Quando o Longhorn Manager é solicitado a criar um volume, ele cria uma instância do Longhorn Engine no nó ao qual o volume está anexado e cria uma réplica em cada nó onde uma réplica será colocada. As réplicas devem ser colocadas em hosts separados para garantir a máxima disponibilidade.
Os múltiplos caminhos de dados para as réplicas garantem a alta disponibilidade de um volume Longhorn. Se ocorrer um problema com uma réplica ou o Engine, isso não afetará todas as réplicas ou o acesso do pod ao volume. O pod continuará a funcionar normalmente. Para um volume dado com uma contagem de réplicas de N, o volume Longhorn pode tolerar um máximo de N-1 falhas de réplica. Isso ocorre porque pelo menos uma réplica saudável é necessária para que o volume permaneça operacional.
O Longhorn Engine sempre é executado no mesmo nó que o Pod que utiliza o SUSE Storage volume. Ele replica o volume de forma síncrona entre as múltiplas réplicas armazenadas em múltiplos nós.
O Engine e as réplicas são orquestrados usando Kubernetes.
Na figura abaixo,
-
Existem três instâncias com SUSE Storage volumes.
-
Cada volume tem um controlador dedicado, chamado Longhorn Engine. Para volumes V1, o engine é executado como um processo Linux, enquanto para volumes V2, ele opera como um dispositivo de bloco RAID SPDK (bdev).
-
Cada SUSE Storage volume tem duas réplicas. No V1, as réplicas são executadas como processos Linux, enquanto no V2, elas são implementadas como bdevs de volume lógico SPDK.
-
As setas na figura indicam o fluxo de dados de leitura/gravação entre o volume, a instância do controlador, as instâncias de réplica e os discos.
-
Ao criar um Longhorn Engine separado para cada volume, se um controlador falhar, a função dos outros volumes não é impactada.
Figura 1. Fluxo de Dados de Leitura/Gravação entre o Volume, Longhorn Engine, Instâncias de Réplica e Discos

1.2. Vantagens de um Design Baseado em Microserviços
Cada Engine só precisa atender a um volume, simplificando o design dos controladores de armazenamento. Como o domínio de falha do software do controlador é isolado a volumes individuais, uma falha do controlador impactará apenas um volume.
O Longhorn Engine é simples e leve, permitindo-nos criar milhares de instâncias separadas do Longhorn Engine. O Kubernetes agenda essas instâncias separadas do Longhorn Engine, extraindo recursos de um conjunto compartilhado de discos e trabalhando com SUSE Storage para formar um sistema de armazenamento em blocos distribuído resiliente.
Como cada volume possui seu próprio controlador, as instâncias do controlador e da réplica para cada volume também podem fazer upgrade sem causar uma interrupção perceptível nas operações de IO.
SUSE Storage pode criar um trabalho de longa duração para orquestrar o upgrade de todos os volumes ativos sem interromper a operação em andamento do sistema. Para garantir que um upgrade não cause problemas imprevistos, SUSE Storage pode optar por fazer upgrade de um pequeno subconjunto dos volumes e reverter para a versão antiga se algo der errado durante o upgrade.
1.3. Driver CSI
O driver CSI do Longhorn pega o dispositivo de bloco, formata-o e o monta no nó. Em seguida, o kubelet monta o dispositivo dentro de um Pod do Kubernetes. Isso permite que o Pod acesse o SUSE Storage volume.
As imagens necessárias do driver CSI do Kubernetes serão implantadas automaticamente pelo implantador do driver Longhorn. Para instalar SUSE Storage em um ambiente air gap, consulte esta seção.
1.4. Plugin CSI
SUSE Storage é gerenciado no Kubernetes através de um Plugin CSI. Isso permite uma fácil instalação do plugin.
O plugin CSI do Kubernetes chama SUSE Storage para criar volumes que geram dados persistentes para uma carga de trabalho do Kubernetes. O plugin CSI oferece a capacidade de criar, excluir, anexar, desanexar, montar o volume e tirar instantâneas do volume. Toda a outra funcionalidade fornecida por SUSE Storage é implementada através da interface do usuário.
O cluster Kubernetes usa internamente a interface CSI para se comunicar com o plugin CSI do Longhorn. E o plugin CSI do Longhorn se comunica com o Longhorn Manager usando a API do Longhorn.
Para volumes v1, SUSE Storage usa iSCSI, o que pode exigir configuração adicional em seus nós:
-
Dependendo da distribuição Linux, você precisa instalar
open-iscsiouiscsiadm.
Em contraste, os volumes v2 vêm com pré-requisitos diferentes, dependendo da configuração:
-
Módulos do kernel como
vfio_pcieuio_pci_genericsão necessários. -
Para o frontend NVMe-TCP, o módulo
nvme_tcpé necessário.
1.5. A interface do usuário
A interface do usuário interage com o Longhorn Manager através da API do Longhorn e atua como um complemento do Kubernetes. Através da interface do usuário, você pode gerenciar snapshots, backups, nós e discos.
Além disso, o uso de espaço dos nós trabalhadores do cluster é coletado e ilustrado pela interface do usuário. Veja aqui para detalhes.
2. Volumes e Armazenamento Primário
Ao criar um volume, o Longhorn Manager cria o microserviço Longhorn Engine e as réplicas para cada volume como microserviços. Juntos, esses microserviços formam um SUSE Storage volume. Cada réplica deve ser colocada em um nó diferente ou em discos diferentes.
Depois que o Longhorn Engine é criado pelo Longhorn Manager, ele se conecta às réplicas. O Engine expõe um dispositivo de bloco no mesmo nó onde o Pod está sendo executado.
Um SUSE Storage volume pode ser criado com kubectl.
2.1. Provisionamento fino e Tamanho do Volume
SUSE Storage é um sistema de armazenamento com provisionamento fino. Isso significa que um SUSE Storage volume ocupará apenas o espaço que precisa no momento. Por exemplo, se você alocou um volume de 20 GB, mas usa apenas 1 GB dele, o tamanho real dos dados no seu disco seria de 1 GB. Você pode ver o tamanho real dos dados nos detalhes do volume na interface do usuário.
Um SUSE Storage volume em si não pode encolher de tamanho se você removeu conteúdo do seu volume. Por exemplo, se você criar um volume de 20 GB, usar 10 GB e depois remover o conteúdo de 9 GB, o tamanho real no disco ainda seria 10 GB em vez de 1 GB. Isso acontece porque SUSE Storage opera no nível de bloco, não no nível do sistema de arquivos, então SUSE Storage não sabe se o conteúdo foi removido por um usuário ou não. Essa informação é mantida principalmente no nível do sistema de arquivos.
Para mais introduções sobre os conceitos relacionados ao tamanho do volume, veja este doc para mais detalhes.
2.2. Revertendo Volumes em Modo de Manutenção
Quando um volume é anexado pela interface do usuário, há uma caixa de seleção para o modo de manutenção. É usado principalmente para reverter um volume de um instantâneo.
A opção resultará em anexar o volume sem habilitar o frontend (dispositivo de bloco ou iSCSI), para garantir que ninguém possa acessar os dados do volume quando o volume estiver anexado.
Após a versão v0.6.0, a operação de reversão de instantâneo exigia que o volume estivesse em modo de manutenção. Isso ocorre porque, se o conteúdo do dispositivo de bloco for modificado enquanto o volume estiver montado ou sendo usado, isso causará corrupção do sistema de arquivos.
Também é útil inspecionar o estado do volume sem se preocupar com os dados sendo acessados acidentalmente.
2.3. Réplicas
Cada réplica contém uma cadeia de instantâneos de um SUSE Storage volume. Um instantâneo é como uma camada de uma imagem, com o instantâneo mais antigo usado como a camada base e os instantâneos mais novos em cima. Os dados só são incluídos em um novo instantâneo se sobrescreverem dados em um instantâneo mais antigo. Juntas, uma cadeia de instantâneos mostra o estado atual dos dados.
Para cada SUSE Storage volume, várias réplicas do volume devem ser executadas no cluster Kubernetes, cada uma em um nó separado. Todas as réplicas são tratadas da mesma forma, e o Longhorn Engine sempre é executado no mesmo nó que o pod, que também é o consumidor do volume. Dessa forma, garantimos que mesmo se o Pod estiver fora do ar, o Engine pode ser movido para outro Pod e seu serviço continuará sem interrupções.
A contagem padrão de réplicas pode ser alterada nas configurações. Quando um volume está anexado, a contagem de réplicas para o volume pode ser alterada na interface do usuário.
Se a contagem atual de réplicas saudáveis for menor do que a contagem de réplicas especificada, SUSE Storage começará a reconstruir novas réplicas.
Se a contagem atual de réplicas saudáveis for maior do que a contagem de réplicas especificada, o Balanceamento Automático de Réplicas e a Localidade de Dados estão desativados, SUSE Storage não fará nada. Nessa situação, se uma réplica falhar ou for excluída, SUSE Storage não começará a reconstruir novas réplicas, a menos que a contagem de réplicas saudáveis caia abaixo da contagem de réplicas especificada. Se o Balanceamento Automático de Réplicas ou a Localidade de Dados estiverem configurados, SUSE Storage pode excluir uma das réplicas.
As réplicas SUSE Storage são construídas usando arquivos sparse files, do Linux que suportam provisionamento fino.
2.3.1. Como Funcionam as Operações de Leitura e Gravação para Réplicas
Quando os dados são lidos de uma réplica de um volume, se os dados puderem ser encontrados nos dados ao vivo, então esses dados são utilizados. Caso contrário, o instantâneo mais recente será lido. Se os dados não forem encontrados no instantâneo mais recente, o próximo instantâneo mais antigo é lido, e assim por diante, até que o instantâneo mais antigo seja lido.
Quando você tira um instantâneo, um disco de diferenciação é criado. À medida que o número de instantâneos cresce, a cadeia de discos de diferenciação (também chamada de cadeia de instantâneos) pode ficar bastante longa. Para melhorar o desempenho de leitura, SUSE Storage portanto mantém um índice de leitura que registra qual disco de diferenciação contém dados válidos para cada bloco de armazenamento de 4K.
Na figura a seguir, o volume tem oito blocos. O índice de leitura tem oito entradas e é preenchido de forma preguiçosa à medida que as operações de leitura ocorrem.
Uma operação de gravação redefine o índice de leitura, fazendo com que ele aponte para os dados ao vivo. Os dados ao vivo consistem em dados em alguns índices e espaço vazio em outros índices.
Além do índice de leitura, atualmente não mantemos metadados adicionais para indicar quais blocos estão sendo usados.
Figura 2. Como o índice de leitura acompanha qual instantâneo contém os dados mais recentes
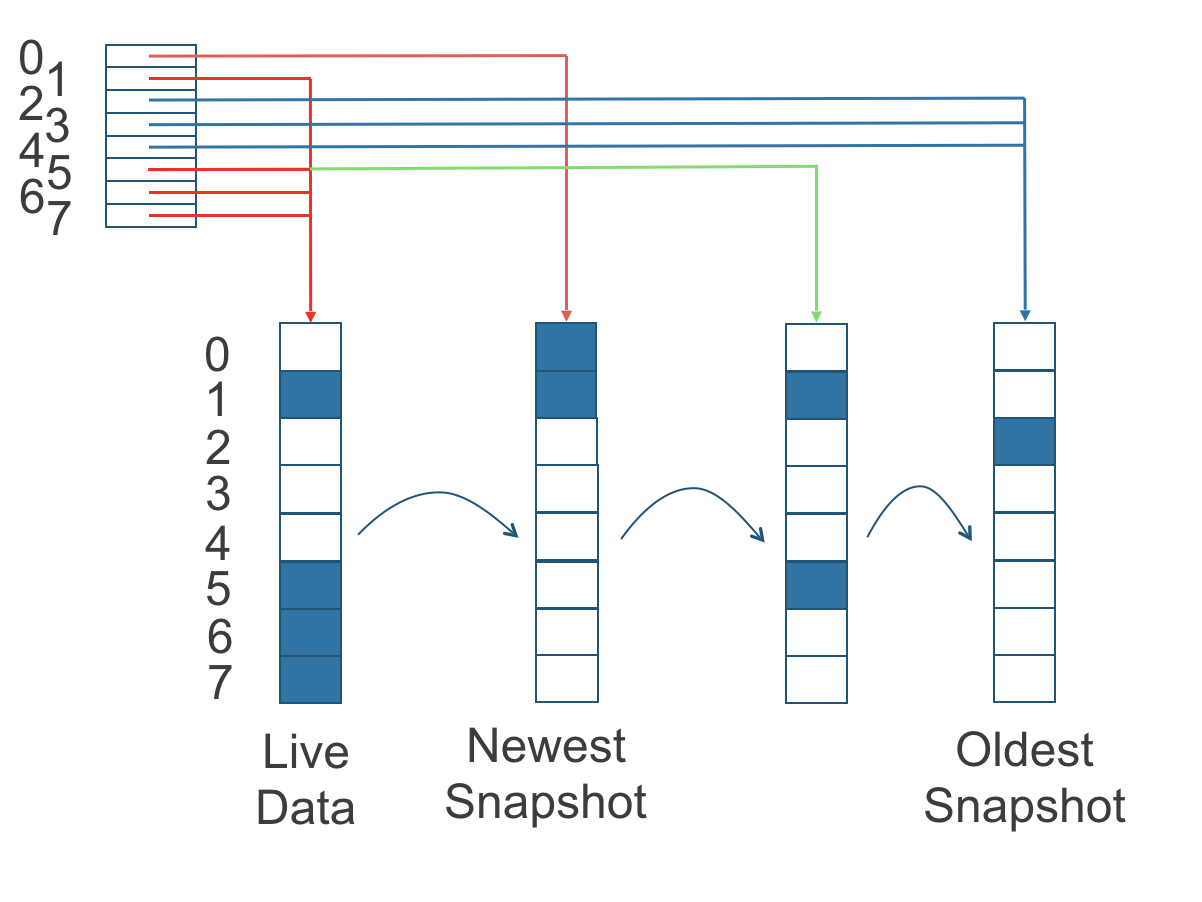
A figura acima é codificada por cores para mostrar quais blocos contêm os dados mais recentes de acordo com o índice de leitura, e a fonte dos dados mais recentes também está listada na tabela abaixo:
| Índice de Leitura | Fonte dos dados mais recentes |
|---|---|
0 |
Instantâneo mais recente |
1 |
Dados ao vivo |
2 |
Instantâneo mais antigo |
3 |
Instantâneo mais antigo |
4 |
Instantâneo mais antigo |
5 |
Dados ao vivo |
6 |
Dados ao vivo |
7 |
Dados ao vivo |
Observe que, como a seta verde mostra na figura acima, o Índice 5 do índice de leitura anteriormente apontava para o segundo instantâneo mais antigo como a fonte dos dados mais recentes, depois mudou para apontar para os dados ao vivo quando o bloco de armazenamento de 4K no Índice 5 foi sobrescrito pelos dados ao vivo.
O índice de leitura é mantido na memória e consome um byte para cada bloco de 4K. O índice de leitura do tamanho de um byte significa que você pode ter até 254 instantâneos para cada volume.
O índice de leitura consome uma certa quantidade de estrutura de dados em memória para cada réplica. Um volume de 1 TB, por exemplo, consome 256 MB de índice de leitura em memória.
2.3.2 Como Novas Réplicas São Adicionadas
Quando uma nova réplica é adicionada, as réplicas existentes são sincronizadas com a nova réplica. A primeira réplica é criada tirando um novo instantâneo dos dados ao vivo.
Os passos a seguir mostram uma descrição mais detalhada de como SUSE Storage adiciona novas réplicas:
-
O Longhorn Engine é pausado.
-
Vamos supor que a cadeia de instantâneos dentro da réplica consiste nos dados ao vivo e em um instantâneo. Quando a nova réplica é criada, os dados ao vivo se tornam o instantâneo mais recente (segundo) e uma nova versão em branco dos dados ao vivo é criada.
-
A nova réplica é criada em modo WO (somente gravação).
-
O Longhorn Engine é retomado.
-
Todos os instantâneos estão sincronizados.
-
A nova réplica está configurada para o modo RW (leitura/gravação).
2.3.3. Como Réplicas Defeituosas são Reconstruídas
SUSE Storage sempre tentará manter pelo menos o número dado de réplicas saudáveis para cada volume.
Quando o controlador detecta falhas em uma de suas réplicas, ele marca a réplica como estando em estado de erro. O Longhorn Manager é responsável por iniciar e coordenar o processo de reconstrução da réplica defeituosa.
Para reconstruir a réplica defeituosa, o Longhorn Manager cria uma réplica em branco e chama o Longhorn Engine para adicionar a réplica em branco ao conjunto de réplicas do volume.
Para adicionar a réplica em branco, o Engine realiza as seguintes operações:
-
Pausa todas as operações de leitura e gravação.
-
Adiciona a réplica em branco no modo WO (somente gravação).
-
Tira um instantâneo de todas as réplicas existentes, que agora terão um disco de diferenciação em branco no início.
-
Retoma todas as operações de leitura e gravação. Apenas operações de gravação serão enviadas para a réplica recém-adicionada.
-
Inicia um processo em segundo plano para sincronizar todos, exceto o disco de diferenciação mais recente, de uma boa réplica para a réplica em branco.
-
Após a sincronização ser concluída, todas as réplicas agora têm dados consistentes, e o gerenciador de volumes define a nova réplica para o modo RW (leitura-gravação).
Finalmente, o Longhorn Manager chama o Longhorn Engine para remover a réplica defeituosa de seu conjunto de réplicas.
2.4. Instantâneos
O recurso de instantâneo permite que um volume seja revertido a um determinado ponto na história. Backups em armazenamento secundário também podem ser criados a partir de um instantâneo.
Quando um volume é restaurado a partir de um instantâneo, ele reflete o estado do volume no momento em que o instantâneo foi criado.
O recurso de instantâneo também faz parte do SUSE Storage processo de reconstrução. Toda vez que SUSE Storage detecta que uma réplica está fora do ar, ele automaticamente tira um instantâneo (sistema) e começa a reconstruí-lo em outro nó.
2.4.1. Como os instantâneos funcionam
Um instantâneo é como uma camada de uma imagem, com o instantâneo mais antigo usado como a camada base e os instantâneos mais novos em cima. Os dados só são incluídos em um novo instantâneo se sobrescreverem dados em um instantâneo mais antigo. Juntas, uma cadeia de instantâneos mostra o estado atual dos dados. Para uma explicação mais detalhada de como os dados são lidos de uma réplica, consulte a seção sobre operações de leitura e gravação para réplicas.
Os instantâneos não podem ser alterados após serem criados, a menos que um instantâneo seja excluído, caso em que suas alterações são fundidas com o próximo instantâneo mais recente. Novos dados são sempre gravados nos dados ao vivo. Novos instantâneos são sempre criados a partir de dados ao vivo.
Para criar um novo instantâneo, os dados ao vivo se tornam o instantâneo mais recente. Em seguida, uma nova versão em branco dos dados ao vivo é criada, substituindo os dados ao vivo antigos.
2.4.2. Instantâneos Recorrentes
Para reduzir o espaço ocupado pelos instantâneos, o usuário pode agendar um instantâneo ou backup recorrente com um número de instantâneos a serem mantidos, que criará automaticamente um novo instantâneo/backup conforme o agendamento, e depois limpará quaisquer instantâneos/backups excessivos.
2.4.3. Apagando instantâneos
Instantâneos indesejados podem ser excluídos manualmente através da interface do usuário. Quaisquer instantâneos gerados pelo sistema serão automaticamente marcados para exclusão se a exclusão de qualquer instantâneo for acionada.
O instantâneo mais recente não pode ser excluído. Isso ocorre porque sempre que um instantâneo é excluído, SUSE Storage fundirá seu conteúdo com o próximo instantâneo, de modo que o próximo e os instantâneos posteriores mantenham o conteúdo correto.
Mas SUSE Storage não pode fazer isso para o instantâneo mais recente, uma vez que não há um instantâneo mais recente para ser fundido com o instantâneo excluído. O próximo “snapshot” do instantâneo mais recente é o volume ativo (cabeça do volume), que está sendo lido/gravado pelo usuário no momento, portanto, o processo de fusão não pode acontecer.
Em vez disso, o instantâneo mais recente será marcado como removido, e será limpo na próxima vez que possível.
Para limpar o instantâneo mais recente, um novo instantâneo pode ser criado, e então o "mais recente" instantâneo anterior pode ser removido.
2.4.4. Armazenando instantâneos
Os instantâneos são armazenados localmente, como parte de cada réplica de um volume. Eles são armazenados no disco dos nós dentro do cluster Kubernetes. Os instantâneos são armazenados no mesmo local que os dados do volume no disco físico do host.
2.4.5. Consistência em caso de falha
SUSE Storage é uma solução de armazenamento em blocos consistente em caso de falha.
É normal que o sistema operacional mantenha conteúdo no cache antes de gravar na camada de blocos. Isso significa que, se todas as réplicas estiverem fora do ar, então SUSE Storage pode não conter as alterações que ocorreram imediatamente antes da interrupção, porque o conteúdo foi mantido no cache do nível do sistema operacional e ainda não foi transferido para o sistema SUSE Storage.
Esse problema é semelhante a problemas que podem ocorrer se o seu computador desktop desligar devido a uma queda de energia. Após retomar a energia, você pode encontrar alguns arquivos corrompidos no disco rígido.
Para forçar os dados a serem gravados na camada de blocos a qualquer momento, o comando de sincronização pode ser executado manualmente no nó, ou o disco pode ser desmontado. O sistema operacional escreveria o conteúdo do cache na camada de blocos em qualquer uma das situações.
SUSE Storage executa o comando sync automaticamente antes de criar um instantâneo.
3. Backup e Armazenamento Secundário
Um backup é um objeto no backupstore, que é um armazenamento de objetos compatível com NFS ou S3 externo ao cluster Kubernetes. Os backups fornecem uma forma de armazenamento secundário para que, mesmo que seu cluster Kubernetes fique indisponível, seus dados ainda possam ser recuperados.
Como a replicação de volume é sincronizada e devido à latência da rede, é difícil fazer replicação entre regiões. O backupstore também é usado como um meio para resolver esse problema.
Quando o alvo de backup é configurado na interface (Backup e Restauração → Alvos de Backup), SUSE Storage pode se conectar ao backupstore e exibir uma lista de backups existentes na tela Backup.
Se SUSE Storage for executado em um segundo cluster Kubernetes, ele também pode sincronizar volumes de recuperação de desastres com os backups no armazenamento secundário, para que seus dados possam ser recuperados mais rapidamente no segundo cluster Kubernetes.
3.1. Como os backups funcionam
Um backup é criado usando um instantâneo como fonte, de modo que reflita o estado dos dados do volume no momento em que o instantâneo foi criado. Um backup é armazenado remotamente fora do cluster.
Em contraste com um instantâneo, um backup pode ser considerado uma versão achatada de uma cadeia de instantâneos. Semelhante à forma como as informações são perdidas quando uma imagem em camadas é convertida em uma imagem plana, os dados também são perdidos quando uma cadeia de instantâneos é convertida em um backup. Em ambas as conversões, quaisquer dados sobrescritos seriam perdidos.
Como os backups não contêm instantâneos, eles não contêm o histórico de alterações nos dados do volume. Depois que você restaura um volume de um backup, o volume inicialmente contém um instantâneo. Esse instantâneo é uma versão consolidada de todos os instantâneos na cadeia original e reflete os dados ao vivo do volume no momento em que o backup foi criado.
Enquanto os instantâneos podem ter centenas de gigabytes, os backups são feitos de arquivos de 2 MB.
Cada novo backup do mesmo volume original é incremental, detectando e transmitindo os blocos alterados entre instantâneos. Essa é uma tarefa relativamente fácil porque cada instantâneo é um diferencial arquivo e armazena apenas as alterações do último instantâneo. Esse design também significa que, se nenhum bloco tiver mudado e um backup for feito, esse backup no armazenamento de backups mostrará como 0 bytes. No entanto, se você restaurar a partir desse backup, ele ainda conterá todos os dados do volume, uma vez que restaurará os blocos necessários já presentes no armazenamento de backups, que são exigidos para um backup.
Para evitar armazenar um número muito grande de pequenos blocos de armazenamento, SUSE Storage realiza operações de backup usando blocos de 2 MB. Isso significa que, se qualquer bloco de 4K em um limite de 2MB for alterado, SUSE Storage fará backup de todo o bloco de 2MB. Isso oferece o equilíbrio certo entre gerenciabilidade e eficiência.
Figura 3. A Relação entre Backups em Armazenamento Secundário e Instantâneos em Armazenamento Primário
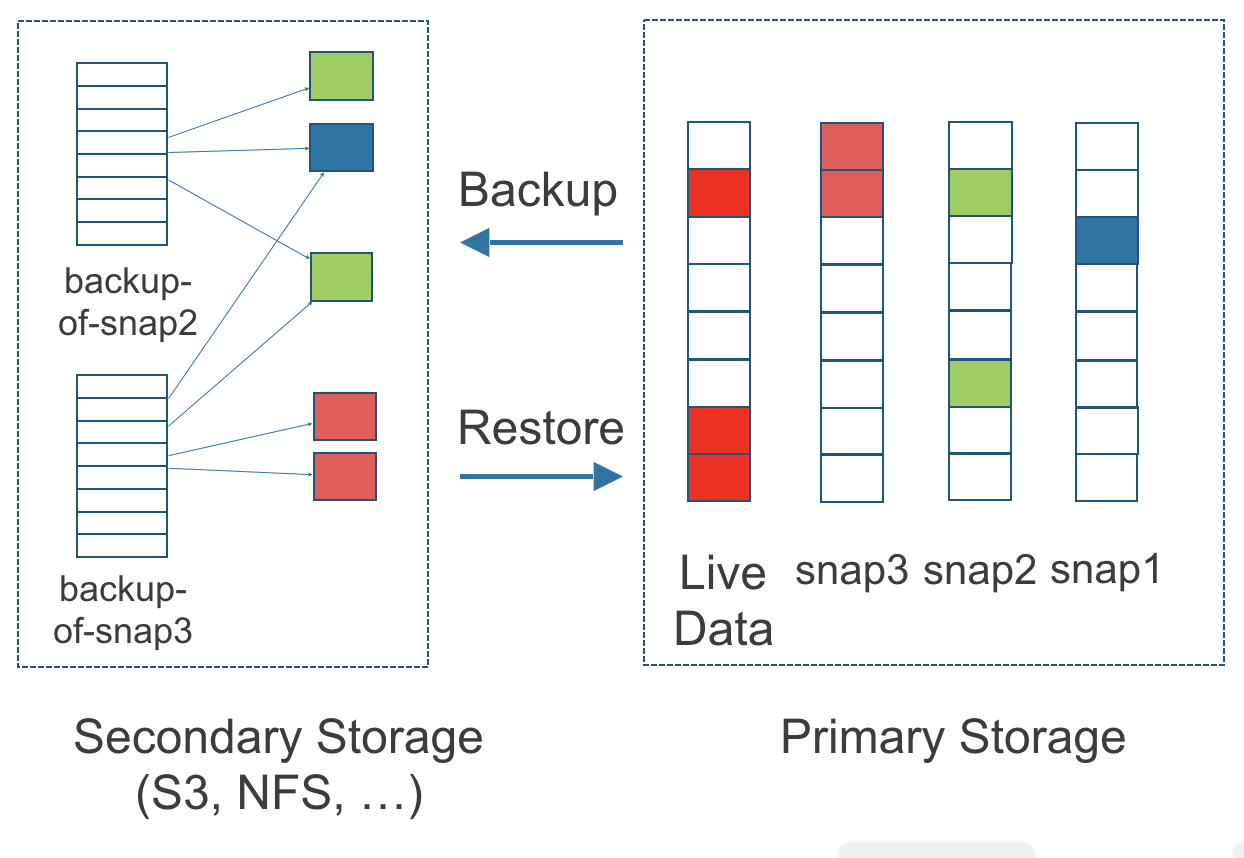
A figura acima descreve como os backups são criados a partir de instantâneos:
-
O lado de Armazenamento Primário do diagrama mostra uma réplica de um volume SUSE Storage no cluster Kubernetes. A réplica consiste em uma cadeia de quatro instantâneos. Em ordem do mais novo para o mais antigo, os instantâneos são Live Data, snap3, snap2 e snap1.
-
O lado de Armazenamento Secundário do diagrama mostra dois backups em um serviço de armazenamento de objetos externo, como o S3.
-
No Armazenamento Secundário, a codificação de cores para o backup a partir do snap2 mostra que inclui tanto a alteração azul do snap1 quanto as alterações verdes do snap2. Nenhuma alteração do snap2 sobrescreveu os dados do snap1, portanto, as alterações de ambos, snap1 e snap2, estão incluídas no backup a partir do snap2.
-
O backup chamado backup-a-partir-do-snap3 reflete o estado dos dados do volume no momento em que o snap3 foi criado. A codificação de cores e as setas indicam que o backup-a-partir-do-snap3 contém todas as alterações vermelho-escuras do snap3, mas apenas uma das alterações verdes do snap2. Isso ocorre porque uma das alterações vermelhas no snap3 sobrescreveu uma das alterações verdes no snap2. Isso ilustra como os backups não incluem todo o histórico de alterações, porque eles mesclam instantâneos com os instantâneos que vieram antes deles.
-
Cada backup mantém seu próprio conjunto de blocos de 2 MB. Cada bloco de 2 MB é salvo apenas uma vez. Os dois backups compartilham um bloco verde e um bloco azul.
Quando um backup é excluído do armazenamento secundário, SUSE Storage não exclui todos os blocos que utiliza. Em vez disso, realiza uma coleta de lixo periodicamente para limpar blocos não utilizados do armazenamento secundário.
Os blocos de 2 MB para todos os backups pertencentes ao mesmo volume são armazenados em um diretório comum e, portanto, podem ser compartilhados entre vários backups.
Para economizar espaço, os blocos de 2 MB que não mudaram entre os backups podem ser reutilizados para múltiplos backups que compartilham o mesmo volume de backup no armazenamento secundário. Como checksums são usados para endereçar os blocos de 2 MB, conseguimos algum grau de deduplicação para os blocos de 2 MB no mesmo volume.
Metadados em nível de volume são armazenados em volume.cfg. Os arquivos de metadados para cada backup (por exemplo, snap2.cfg) são relativamente pequenos porque contêm apenas os offsets e checksums de todos os blocos de 2 MB no backup.
Cada bloco de 2 MB (.blk file) é comprimido.
3.2. Backups Recorrentes
As operações de backup podem ser agendadas usando o recurso de instantâneo e backup recorrente, mas também podem ser feitas conforme necessário.
É recomendado agendar backups recorrentes para seus volumes. Se um backupstore não estiver disponível, é recomendado agendar o snapshot recorrente em vez disso.
A criação de backup envolve copiar os dados pela rede, portanto, levará tempo.
3.3. Volumes de Recuperação de Desastre
Um volume de recuperação de desastre (DR) é um volume especial que armazena dados em um cluster de backup caso todo o cluster principal falhe. Os volumes DR são usados para aumentar a resiliência dos volumes SUSE Storage.
Como o principal objetivo de um volume DR é restaurar dados do backup, esse tipo de volume não suporta as seguintes ações antes de ser ativado:
-
Criar, excluir e reverter instantâneos
-
Criando backups
-
Criar volumes persistentes
-
Criar solicitações de volume persistente
Um volume DR pode ser criado a partir do backup de um volume no backupstore. Após a criação do volume DR, SUSE Storage monitorará seu volume de backup original e restaurará incrementalmente a partir do último backup. Um volume de backup é um objeto no backupstore que contém múltiplos backups do mesmo volume.
Se o volume original no cluster principal falhar, o volume DR pode ser ativado imediatamente no cluster de backup, reduzindo o tempo necessário para restaurar os dados do backupstore para o volume no cluster de backup.
Quando um volume DR é ativado, SUSE Storage verificará o último backup do volume original. Se esse backup ainda não tiver sido restaurado, a restauração será iniciada e a ação de ativação falhará. Os usuários precisam aguardar a conclusão da restauração antes de tentar novamente.
O Destino de Backup nas configurações não pode ser atualizado se existirem volumes de DR.
Após um volume de DR ser ativado, ele se torna um volume normal SUSE Storage e não pode ser desativado.
3.4. Intervalos de Atualização do Backupstore, RTO e RPO
A restauração incremental é geralmente acionada pela atualização periódica do backupstore. Você pode definir o intervalo de atualização na tela de configurações do destino de backup (Backup e Restauração → Destinos de Backup).
Observe que esse intervalo pode impactar potencialmente o Objetivo de Tempo de Recuperação (RTO). Se for muito longo, pode haver uma grande quantidade de dados para o volume de recuperação de desastres restaurar, o que levará muito tempo.
Quanto ao Objetivo de Ponto de Recuperação (RPO), ele é determinado pela programação recorrente de backups do volume de backup. Se a programação de backup recorrente para o volume normal A cria um backup a cada hora, então o RPO é de uma hora. Você pode verificar aqui como configurar backups recorrentes em SUSE Storage.
A análise a seguir assume que o volume cria um backup a cada hora e que restaurar dados de um backup de forma incremental leva cinco minutos:
-
Se o intervalo de pesquisa do backupstore for de 30 minutos, então haverá no máximo um backup de dados desde a última restauração. O tempo para restaurar um backup é de cinco minutos, então o RTO seria de cinco minutos.
-
Se o intervalo de pesquisa do backupstore for de 12 horas, então haverá no máximo 12 backups de dados desde a última restauração. O tempo para restaurar os backups é 5 * 12 = 60 minutos, então o RTO seria de 60 minutos.
Apêndice: Como o Armazenamento Persistente Funciona no Kubernetes
Para entender o armazenamento persistente no Kubernetes, é importante entender Volumes, PersistentVolumes, PersistentVolumeClaims e StorageClasses, e como eles funcionam juntos.
Uma propriedade importante de um Volume do Kubernetes é que ele tem o mesmo ciclo de vida que o Pod ao qual pertence. O Volume é perdido se o Pod desaparecer. Em contraste, um PersistentVolume continua a existir no sistema até que os usuários o excluam. Os volumes também podem ser usados para compartilhar dados entre contêineres dentro do mesmo Pod, mas esse não é o principal caso de uso, pois os usuários normalmente têm apenas um contêiner por Pod.
Um PersistentVolume (PV) é uma peça de armazenamento persistente no cluster Kubernetes, enquanto um PersistentVolumeClaim (PVC) é um pedido de armazenamento. StorageClasses permitem que seja provisionado dinamicamente novo armazenamento para cargas de trabalho sob demanda.
Como as cargas de trabalho do Kubernetes utilizam armazenamento persistente novo e existente
De maneira geral, existem duas principais formas de usar armazenamento persistente no Kubernetes:
-
Usar um volume persistente existente
-
Provisionar novos volumes persistentes dinamicamente
Provisionamento de Armazenamento existente
Para usar um PV existente, sua aplicação precisará usar um PVC que esteja vinculado a um PV, e o PV deve incluir os recursos mínimos que o PVC requer.
Em outras palavras, um fluxo de trabalho típico para configurar armazenamento existente no Kubernetes é o seguinte:
-
Configurar volumes de armazenamento persistente, no sentido de armazenamento físico ou virtual ao qual você tem acesso.
-
Adicionar um PV que se refere ao armazenamento persistente.
-
Adicionar um PVC que se refere ao PV.
-
Montar o PVC como um volume em sua carga de trabalho.
Quando um PVC solicita uma peça de armazenamento, o servidor de API do Kubernetes tentará combinar esse PVC com um PV pré-alocado à medida que volumes correspondentes se tornem disponíveis. Se uma correspondência puder ser encontrada, o PVC será vinculado ao PV, e o usuário começará a usar essa peça de armazenamento pré-alocada.
Se um volume correspondente não existir, os PersistentVolumeClaims permanecerão não vinculados indefinidamente. Por exemplo, um cluster provisionado com muitos PVs de 50 Gi não corresponderia a um PVC solicitando 100 Gi. O PVC poderia ser vinculado após um PV de 100 Gi ser adicionado ao cluster.
Em outras palavras, você pode criar PVCs ilimitados, mas eles só serão vinculados a PVs se o mestre do Kubernetes puder encontrar um PV suficiente que tenha pelo menos a quantidade de espaço em disco exigida pelo PVC.
Provisionamento Dinâmico de Armazenamento
Para o provisionamento dinâmico de armazenamento, sua aplicação precisará usar um PVC que esteja vinculado a uma StorageClass. A StorageClass contém a autorização para provisionar novos volumes persistentes.
O fluxo de trabalho geral para o provisionamento dinâmico de novo armazenamento no Kubernetes envolve um recurso StorageClass:
-
Adicione uma StorageClass e configure-a para provisionar automaticamente novo armazenamento a partir do armazenamento ao qual você tem acesso.
-
Adicione um PVC que se refere à StorageClass.
-
Monte o PVC como um volume para sua carga de trabalho.
Os administradores de cluster do Kubernetes podem usar uma StorageClass do Kubernetes para descrever a “classes” do armazenamento que oferecem. As StorageClasses podem ter diferentes limites de capacidade, diferentes IOPS ou quaisquer outros parâmetros que o provisionador suporte. O provisionador específico do fornecedor de armazenamento deve ser usado junto com a StorageClass para alocar PV automaticamente, seguindo os parâmetros definidos no objeto StorageClass. Além disso, o provisionador agora tem a capacidade de impor as cotas de recursos e os requisitos de permissão para os usuários. Neste design, os administradores são liberados do trabalho desnecessário de prever a necessidade de PVs e alocá-los.
Quando uma StorageClass é usada, um administrador do Kubernetes não é responsável por alocar cada pedaço de armazenamento. O administrador só precisa dar aos usuários permissão para acessar um determinado pool de armazenamento e decidir a cota para o usuário. Então, o usuário pode reservar os pedaços necessários do armazenamento a partir do pool de armazenamento.
As StorageClasses também podem ser usadas sem criar explicitamente um objeto StorageClass no Kubernetes. Como a StorageClass também é um campo usado para combinar um PVC com um PV, um PV pode ser criado manualmente com um nome de Storage Class personalizado, e então um PVC pode ser criado que solicita um PV com esse nome de StorageClass. O Kubernetes pode então vincular seu PVC ao PV com o nome de StorageClass especificado, mesmo que o objeto StorageClass não exista como um recurso do Kubernetes.
SUSE Storage introduz uma StorageClass para que suas cargas de trabalho do Kubernetes possam reservar pedaços do seu armazenamento persistente conforme necessário.
Escalonamento Horizontal para Cargas de Trabalho do Kubernetes com Armazenamento Persistente
O VolumeClaimTemplate é uma propriedade da especificação do StatefulSet e fornece uma maneira para a solução de armazenamento em bloco escalar horizontalmente para uma carga de trabalho do Kubernetes.
Essa propriedade pode ser usada para criar PVs e PVCs correspondentes para Pods que foram criados por um StatefulSet.
Esses PVCs são criados usando uma StorageClass, então podem ser configurados automaticamente quando o StatefulSet é escalado para cima.
Quando um StatefulSet é escalado para baixo, os PVs/PVCs extras são mantidos no cluster e são reutilizados quando o StatefulSet é escalado para cima novamente.
O VolumeClaimTemplate é importante para soluções de armazenamento em bloco como EBS e SUSE Storage. Porque essas soluções são inerentemente ReadWriteOnce,, não podem ser compartilhadas entre os Pods.
Os Deployments não funcionam bem com armazenamento persistente se você tiver mais de um Pod em execução com dados persistentes. Para mais de um Pod, um StatefulSet deve ser usado.