レプリカ再構築
SUSE Storageが失敗したり削除されたレプリカを検出すると、自動的に再構築プロセスを開始します。この文書は、v1データエンジンのレプリカ再構築ワークフローを概説しており、フル、デルタ、および*高速*再構築方法を含みます。また、各方法に関連する制限についても説明します。
再構築は以下のシナリオでは開始されません:
-
ボリュームが別のノードに移行中です。
-
ボリュームは古い復元/DRボリュームです。
-
ボリュームのサイズが拡大しています。
レプリカ再構築ワークフロー
レプリカ再構築は、v1データエンジンの以下のシナリオで発生する可能性があります:
-
ノードが再起動、排出、または追放されます。
-
レプリカが不健康になるか、削除されます。
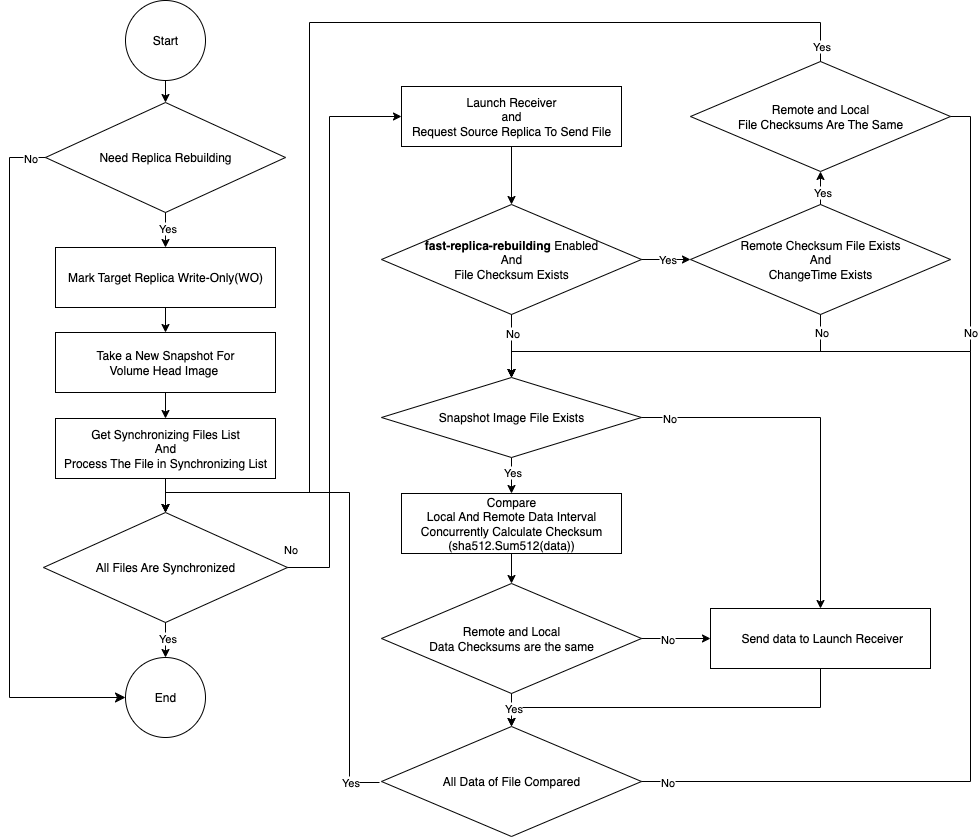
-
ターゲットレプリカを`WO`(書き込み専用)モードでマークします。
-
データ整合性チェックのためのボリュームヘッド参照ポイントとして新しいスナップショットを作成します。
-
ボリュームヘッドおよびスナップショットファイルの同期ファイルリストを生成します。
V1データエンジン用
-
各スナップショットのためにターゲットレプリカで受信サーバーを開始します。
-
ソースレプリカにデータ同期を開始するよう指示します。
-
各スナップショットについて:
-
ターゲットレプリカのデータディレクトリにスナップショットファイルが存在するか確認してください。
-
_いいえ_の場合、ソースレプリカからターゲットレプリカにスナップショットデータ全体を転送します。 [_full_replica_rebuilding]を参照してください。
-
_はい_の場合、スナップショットのチェックサムファイルが存在するか、ターゲットとソースレプリカ間で修正時間とチェックサムが同一であるかを確認します。
-
_はい_の場合、SUSE Storageはスナップショットのデータ転送をスキップします。この最適化により、CPU使用率、ディスクI/O、ネットワークI/O、および全体の再構築時間が削減されます。[_fast_replica_rebuilding]を参照してください。
-
_いいえ_の場合、SUSE StorageはSHA-512アルゴリズムを使用してブロックレベルのチェックサムを計算し、比較します。不一致が見つかった場合、異なるブロックのみが同期されます。 [_delta_replica_rebuilding]を参照してください。
-
-
-
-
V2データエンジン用
-
ソースとターゲットのレプリカを公開し、SPDKエンジンを使用して浅いコピーを準備します。
-
各スナップショットについて:
-
ソースとターゲット間でスナップショットのタイムスタンプ、実際のサイズ、およびチェックサムが一致するか確認します。
-
_はい_の場合、SUSE Storageはそのスナップショットのデータ転送をスキップします。
-
_いいえ_の場合、ソースとターゲットのスナップショットの両方に範囲チェックサムが含まれているか確認します。
-
_はい_の場合、範囲チェックサムを取得して比較します。不一致が存在する場合、不一致の範囲のみがコピーされます。 [_fast_replica_rebuilding]を参照してください。
-
_いいえ_の場合、既存のターゲットスナップショットを削除します。その後、ソースレプリカからターゲットレプリカにスナップショット全体をコピーします。 [_full_replica_rebuilding]を参照してください。
-
-
-
フルレプリカ再構築
レプリカが回復不可能であるか、既存のデータがない場合、SUSE Storageは健全なレプリカからすべてのデータを同期します。フルスナップショットチェーンを転送することによってレプリカを再構築します。
フルレプリカの再構築は、ネットワーク帯域幅を大幅に消費し、ターゲットノードでのディスク書き込み操作が重くなります。ただし、ターゲットレプリカに使用可能なデータがない場合は必要です。
デルタレプリカ再構築
デルタレプリカの再構築はv1データエンジン専用です。再利用可能な失敗したレプリカから始まり、すべてのスナップショットのデータをブロックごとにデータ整合性をチェックします。
-
これは失敗したレプリカの再利用のみに利用可能で、失敗したレプリカのデータディレクトリに同名のスナップショットファイルが存在します。
-
スナップショットにチェックサムがない場合、SUSE Storageはこのスナップショットのためにデルタレプリカ再構築を行います。
-
利点:
-
ネットワーク帯域幅の消費を削減します。
-
-
欠点:
-
データ整合性チェックのため、SUSE Storageはスナップショットデータの各ブロックについてチェックサムを計算し、その結果、CPU負荷が増加します。
-
再構築時間はCPUの性能に影響されます。
-
高速レプリカ再構築
以下の条件が満たされると、高速レプリカ再構築が有効になります:
-
高速レプリカ再構築設定が有効です:
fast-replica-rebuild-enabled: true -
スナップショットチェックサムファイルが作成されます(チェックサムは事前に計算されています)。以下のいずれかの方法を使用して:
-
`snapshot-data-integrity`は`enabled`に設定されています: スケジュールされたジョブが設定された間隔で全スナップショットのチェックサムを計算します(デフォルト:7日)。
-
`snapshot-data-integrity-immediate-check-after-snapshot-creation`は`true`に設定されています: スナップショット作成直後にスナップショットチェックサムが計算されます。
-
|
これらのチェックサム計算はストレージと計算リソースを消費します。 計算時間は予測できず、ストレージパフォーマンスに悪影響を及ぼす可能性があります。 詳細については、スナップショットデータの整合性をご覧ください。 |
-
利点:
-
ネットワーク帯域幅の消費を最小限に抑えます。
-
ディスクI/Oを最小限に抑えます。
-
-
欠点:
-
スナップショットのチェックサムを計算するのは時間がかかる場合があります。
-
チェックサム計算のタイミングは予測できません。高いI/O負荷の下でもトリガーされる可能性があります。
-
詳細については、高速レプリカ再構築をご覧ください。
再構築パフォーマンスに影響を与える要因
-
大きなボリュームヘッド
-
なぜ重要なのか: ボリュームヘッドは、事前に計算されたチェックサムを持たない特別なファイルです。 レプリカが失敗した場合、SUSE Storageは常にボリュームヘッド全体を同期する必要があります。 大きなボリュームヘッドは再構築時間を増加させます。
-
どのように防ぐか: ボリュームヘッドのサイズを減らすために、定期的にスナップショットを取得してください。 再構築時間を最小限に抑えるために、計画されたメンテナンスの前にスナップショットをスケジュールしてください。
-
-
スナップショットが存在しない
-
なぜ重要なのか: スナップショットがない場合、SUSE Storageはデータ転送をスキップしたり、既存のデータを再利用したりすることができません。 ボリュームヘッドのスナップショットが作成されても、そのチェックサムが準備できていない場合、SUSE Storageはデルタ再構築を実行する必要があります。 これにより、ブロックごとのチェックサム比較によるCPU使用率が増加します。
-
どのように防ぐか:
-
チェックサムを事前に計算するには、`snapshot-data-integrity-immediate-check-after-snapshot-creation`または`snapshot-data-integrity`を有効にしてください。 *トレードオフ:*計算中にCPU、ディスクI/O、およびストレージ使用量が増加します。
-
定期的にスナップショットを作成するために、定期ジョブを使用してください。
-
-
-
スナップショットが削除されました
-
なぜ重要なのか: スナップショットの削除が開始されると、システム生成のスナップショットが次のスナップショットに統合されます。 これにより、次のスナップショットのチェックサムが無効になります。
-
どのように防ぐか:
-
削除後にチェックサムが計算されることを保証するには、`snapshot-data-integrity-immediate-check-after-snapshot-creation`を有効にしてください。
-
スナップショットを積極的に作成し、アップグレードや再構築を行う前にチェックサム生成の時間を確保してください。
-
-
-
同時再構築
-
なぜ重要なのか: 同じノードで複数の再構築を実行すると、CPU、ディスク入出力、およびネットワーク入出力が過剰に使用され、パフォーマンスに影響を与える可能性があります。
-
どのように防ぐか: `concurrent-replica-rebuild-per-node-limit`設定を使用して、同時再構築の数を調整してください。
-
-
複数のレプリカエラー
-
なぜ重要なのか: 再構築時間と複雑さが増加します。 `auto-cleanup-system-generated-snapshot`が`true`で、ユーザーが作成したスナップショットが存在しない場合、2つのエラーが発生したレプリカが少なくとも1回の完全データ転送を引き起こす可能性があります。
詳細については、 2つのエラーが発生したレプリカを再構築する際に「完全データ転送」を避けるを参照してください。
-
どのように防ぐか:
-
メンテナンスを行う前に`auto-cleanup-system-generated-snapshot`を無効にしてください。
-
メンテナンスを開始する前に、すべてのボリュームのユーザースナップショットを作成してください。
-
定期的にスナップショットを取得するために、定期ジョブを使用してください。
-
-
-
スケールレプリカ再構築
-
なぜ重要なのか:
スケールレプリカの再構築により、再構築レプリカは複数の正常なレプリカから同時にスナップショットを取得でき、特定のワークロードパターンに対して再構築パフォーマンスが大幅に向上します。
-
有効にする方法:
replica-rebuild-concurrent-sync-limit> 1 に設定して、複数の正常なレプリカが同期サーバーを起動できるようにします。再構築レプリカは、異なるソースレプリカから異なるスナップショットを同時に取得します。この機能は、スナップショットに散在する小さなデータチャンクや穴があるボリュームに特に有益です。詳細については、スケールレプリカ再構築を参照してください。
-
使用例
ノードのアップグレード中の再起動
レプリカを持つワーカーノードが計画的なアップグレードの一環として再起動されるとき:
-
そのノード上のレプリカは一時的に利用できなくなり、エラー状態となりますが、読み取りおよび書き込み操作は継続されます。
-
ノードが`replica-replenishment-wait-interval`内に回復した場合、SUSE Storageは再利用可能なエラーが発生したレプリカを使用して再構築を開始します。
再構築プロセス中:
-
SUSE Storageは、複数の再利用可能なエラーが発生したレプリカが利用可能な場合、最新の再利用可能なエラーが発生したレプリカを選択します。
-
再構築シナリオに基づいて:
-
高速レプリカ再構築が有効で、すべてのスナップショットチェックサムが存在する場合: SUSE Storageが[_fast_replica_rebuilding]をトリガーします。 ボリュームヘッドで変更されたブロックのみが同期され、完全な再構築や差分再構築の両方を回避します。
-
高速レプリカ再構築が有効ですが、一部のスナップショットチェックサムが欠落している場合:SUSE Storageが[_delta_replica_rebuilding]をトリガーします。 チェックサムのないスナップショットで変更されたブロックのみが同期され、完全な再構築を回避します。
-
高速レプリカ再構築が無効な場合:SUSE Storageが*すべて*のスナップショットの変更されたブロックを同期することでデルタ再構築を実行し、完全な再構築を回避します。
-
関連設定
| 設定 | デフォルト | 説明 |
|---|---|---|
|
|
迅速なレプリカ再構築を有効にします。事前に計算されたスナップショットのチェックサムに依存します。 |
|
スナップショットのディスクファイルは、ハッシュされていない場合または変更時刻が変更された場合にのみハッシュ化されます。 |
|
|
|
すべてのスナップショットのチェックサムを計算するためのcronスケジュール。デフォルト:7日ごと。 |
|
|
有効にすると、スナップショット作成後すぐにチェックサムを計算します。 |
|
|
新しいレプリカを作成する前に待機する秒数。エラーとなったレプリカの再利用を許可します。 |
|
|
ノードごとの同時レプリカ再構築の数を制限します。 |
|
|
再構築中のレプリカに同時に同期できる健康なレプリカの最大数。範囲:1-5.1 に設定すると、スケール再構築が無効になります。 |
|
|
ボリュームが切り離されている間に劣化したレプリカが再構築されるかどうかを決定します。 |
設定のトレードオフ分析
-
-
enabled: チェックサムが最新の場合、スナップショットデータ転送をスキップします。高速な再構築を提供しますが、データの再検証は行いません。 -
disabled: ブロック比較を使用してデルタ再構築を実行します。遅くなりますが、スナップショットデータの整合性を確保します。
-
-
-
enabled: デフォルトでは、スナップショットのチェックサムを7日ごとに計算します。CPU、ディスク I/O、およびリソースの使用量が増加します。
-
-
snapshot-data-integrity-cronjob
-
デフォルト:
0 0 */7 * *`snapshot-data-integrity`が有効な場合、これはスナップショットのチェックサムが再計算されるタイミングを定義します。cron実行の間に作成されたスナップショットにはチェックサムがない場合があります。
-
-
snapshot-data-integrity-immediate-check-after-snapshot-creation
-
true: 作成後すぐにスナップショットのチェックサムを計算します。CPUおよびディスクI/Oの使用量が増加します。完了時間は予測できません。 -
false: スナップショットには次のcron実行までチェックサムがない場合があります。チェックサムが欠落している場合、デルタ再構築が必要になります。
-
-
replica-replenishment-wait-interval
-
デフォルト:
600秒-
短い間隔: エラーとなったレプリカの再利用をスキップし、完全な再構築をトリガーする可能性があります。
-
長い間隔: エラーとなったレプリカを再利用するまでの待機時間が長くなりますが、回復が遅れる可能性があります。
-
-
-
concurrent-replica-rebuild-per-node-limit
-
デフォルト:
5-
高い制限: ノードリソースが過負荷になる可能性があり、再構築やアクティブなワークロードが遅くなります。
-
低制限: リソースの競合を減少させますが、キューイングのため再構築時間が増加します。
-
-
-
replica-rebuild-concurrent-sync-limit
-
デフォルト:
1-
`1`に設定すると、スケール再構築が無効になり、最小限のリソース消費で従来の単一ソース再構築のみが使用されます。値が2から5に設定されると、複数のソースレプリカを使用したスケール再構築が有効になり、ボリュームのパフォーマンスが大幅に向上します。ただし、高い値はソースおよび宛先レプリカのCPU消費を増加させます。
-
この設定は、ボリューム単位で`volume.spec.RebuildConcurrentSyncLimit`によって上書きできます。
-
-